
💎 Kafka面试题集合
目录
- Kafka入门
- Kafka的架构设计
- Kafka的数据模型与消息存储机制
- Kafka副本同步机制
- Kafka选举机制
- Kafka副本数据一致性
- 消息顺序性
- 如何确保消息不丢失
- 生产者消息发送流程
- 消费者消费消息流程
- Kafka消息积压问题
Kafka入门
什么是消息队列与Kafka简介
消息队列(Message Queue,简称MQ),指保存消息的一个容器,本质是个队列。
**消息(Message)**是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
**消息队列(Message Queue)**是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
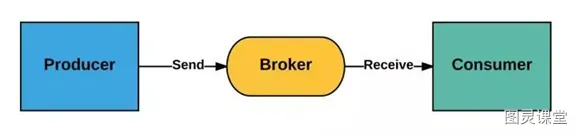
核心组件:
- Producer:消息生产者,负责产生和发送消息到Broker
- Broker:消息处理中心。负责消息存储、确认、重试等,一般其中会包含多个queue
- Consumer:消息消费者,负责从Broker中获取消息,并进行相应处理
为什么需要消息队列?
- 屏蔽异构平台的细节:发送方、接收方系统之间不需要了解双方,只需认识消息
- 异步:消息堆积能力;发送方接收方不需同时在线,发送方接收方不需同时扩容(削峰)
- 解耦:防止引入过多的API给系统的稳定性带来风险;调用方使用不当会给被调用方系统造成压力,被调用方处理不当会降低调用方系统的响应能力
- 复用:一次发送多次消费
- 可靠:一次保证消息的传递。如果发送消息时接收者不可用,消息队列会保留消息,直到成功地传递它
- 提供路由:发送者无需与接收者建立连接,双方通过消息队列保证消息能够从发送者路由到接收者,甚至对于本来网络不易互通的两个服务,也可以提供消息路由
消息队列有什么优点和缺点?
核心优点
- 解耦
- 异步
- 削峰
缺点
- 系统可用性降低:系统引入的外部依赖越多,越容易挂掉
- 系统复杂度提高了
- 一致性问题:消息传递给多个系统,部分执行成功,部分执行失败,容易导致数据不一致
Kafka简介
Kafka是一个分布式流处理系统,流处理系统使它可以像消息队列一样publish或者subscribe消息,分布式提供了容错性,并发处理消息的机制。
Kafka的优势和特点
- 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的性能
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失,异步化处理机制
- 持久化:将消息持久化到磁盘。通过将数据持久化到硬盘以及replica(follower节点)防止数据丢失
- 零拷贝:减少了很多的拷贝技术,以及可以总体减少阻塞事件,提高吞吐量
- 可靠性:Kafka是分布式,分区,复制和容错的
Kafka的特点:
- 顺序读,顺序写
- 利用Linux的页缓存
- 分布式系统,易于向外扩展。所有的Producer、Broker和Consumer都会有多个,均为分布式的。无需停机即可扩展机器。多个Producer、Consumer可能是不同的应用
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡
- 支持online(在线)和offline(离线)的场景
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言
Kafka与传统消息队列的对比
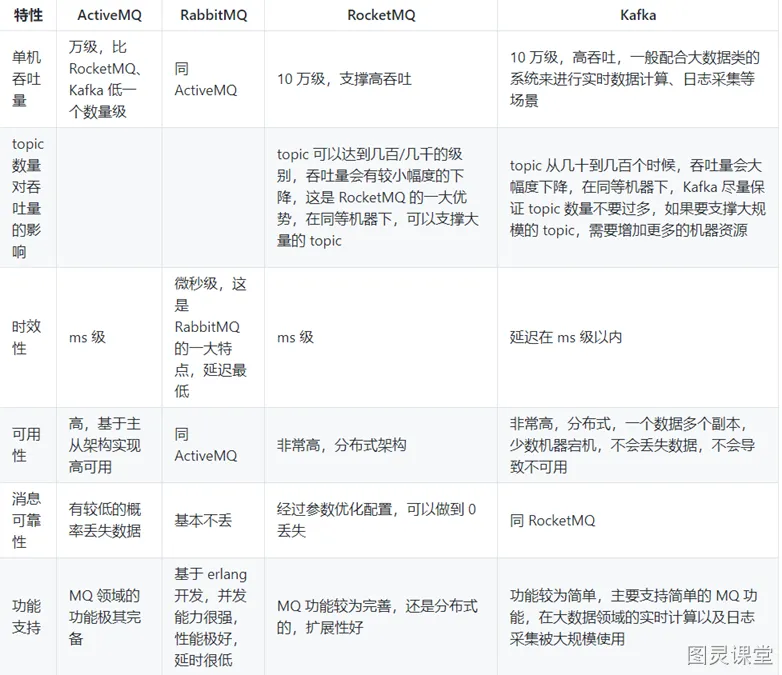
各种对比之后,有如下建议:
- ActiveMQ:没经过大规模吞吐量场景的验证,社区也不是很活跃,所以不推荐
- RabbitMQ:虽然erlang语言阻止了大量的Java工程师去深入研究和掌控它,对公司而言,几乎处于不可控的状态,但是毕竟是开源的,比较稳定的支持,活跃度也高,推荐中小型公司使用;推荐
- RocketMQ:阿里出品,Java语言编写,经过了阿里多年双十一大促的考验,性能和稳定性得到了充分的严重。目前在业界被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binlog分发等场景;强烈推荐
- Kafka:如果是大数据领域的实时计算、日志采集等场景,用Kafka是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
Kafka的架构设计
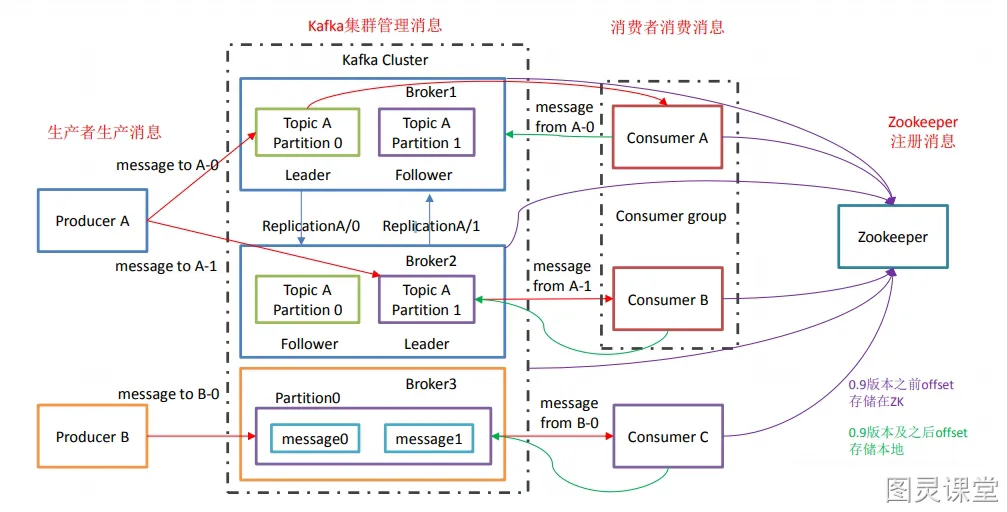
Kafka运行在集群上,集群包含一个或多个服务器。Kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时间戳(timestamp)。
基本概念
- Producer:消息生产者,就是向kafka broker发消息的客户端
- Consumer:消息消费者,是消息的使用方,负责消费Kafka服务器上的消息
- Topic:主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息
- Partition:消息分区,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
- Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic
- Consumer Group:消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群
- Offset:消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息
消息和批次
消息,Kafka里的数据单元,也就是我们一般消息中间件里的消息的概念(可以比作数据库中一条记录)。消息由字节数组组成。消息还可以包含键(可选元数据,也是字节数组),主要用于对消息选取分区。
作为一个高效的消息系统,为了提高效率,消息可以被分批写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息,会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡(时间延迟和吞吐量之间),批次里包含的消息越多,单位时间内处理的消息就越多,单个消息的传输时间就越长(吞吐量高延时也高)。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
对于Kafka来说,消息是晦涩难懂的字节数组,一般我们使用序列化和反序列化技术,格式常用的有JSON和XML,还有Avro(Hadoop开发的一款序列化框架),具体怎么使用依据自身的业务来定。
主题和分区
Kafka里的消息用主题进行分类(主题好比数据库中的表),主题下有可以被分为若干个分区(分表技术)。分区本质上是个提交日志文件,有新消息,这个消息就会以追加的方式写入分区(写文件的形式),然后用先入先出的顺序读取。
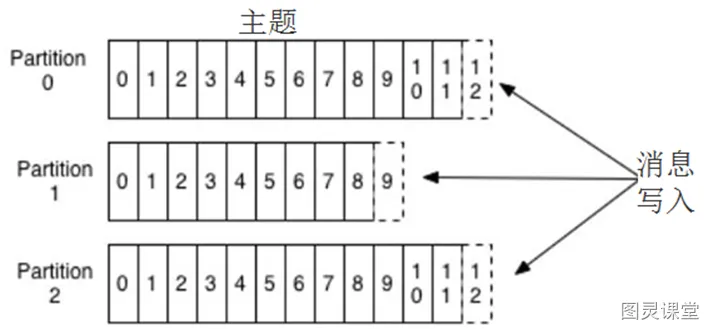
但是因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器(这是Kafka高性能的一个原因,多台服务器的磁盘读写性能比单台更高)。前面我们说Kafka可以看成一个流平台,很多时候,我们会把一个主题的数据看成一个流,不管有多少个分区。
生产者和消费者、偏移量、消费者群组
就是一般消息中间件里生产者和消费者的概念。一些其他的高级客户端API,像数据管道API和流式处理的Kafka Stream,都是使用了最基本的生产者和消费者作为内部组件,然后提供了高级功能。
生产者默认情况下把消息均衡分布到主题的所有分区上,如果需要指定分区,则需要使用消息里的消息键和分区器。
消费者订阅主题,一个或者多个,并且按照消息的生成顺序读取。消费者通过检查所谓的偏移量来区分消息是否读取过。偏移量是一种元数据,一个不断递增的整数值,创建消息的时候,Kafka会把他加入消息。在一个主题中一个分区里,每个消息的偏移量是唯一的。每个分区最后读取的消息偏移量会保存到Zookeeper或者Kafka上,这样分区的消费者关闭或者重启,读取状态都不会丢失。
多个消费者可以构成一个消费者群组。怎么构成?共同读取一个主题的消费者们,就形成了一个群组。群组可以保证每个分区只被一个消费者使用。
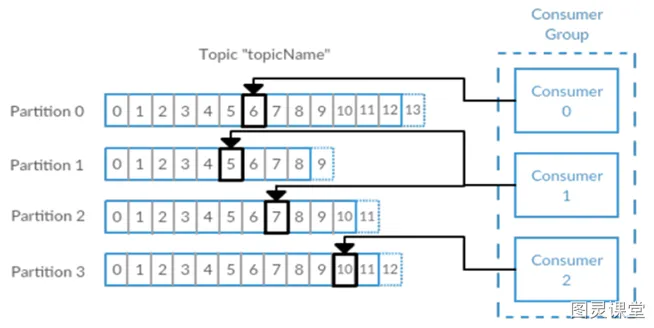
消费者和分区之间的这种映射关系叫做消费者对分区的所有权关系,很明显,一个分区只有一个消费者,而一个消费者可以有多个分区。Kafka区别于其他MQ之一(吃饭的故事:一桌一个分区,多桌多个分区,生产者不断生产消息(消费),消费者就是买单的人,消费者群组就是一群买单的人),一个分区只能被消费者群组中的一个消费者消费(不能重复消费),如果有一个消费者挂掉了<James跑路了>,另外的消费者接上)
Broker和集群
一个独立的Kafka服务器叫Broker。
broker的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求,返回消息。在合适的硬件上,单个broker可以处理上千个分区和每秒百万级的消息量。(要达到这个目的需要做操作系统调优和JVM调优)
多个broker可以组成一个集群。每个集群中broker会选举出一个集群控制器。控制器会进行管理,包括将分区分配给broker和监控broker。
集群里,一个分区从属于一个broker,这个broker被称为首领。但是分区可以被分配给多个broker,这个时候会发生分区复制。
集群中Kafka内部一般使用管道技术进行高效的复制。
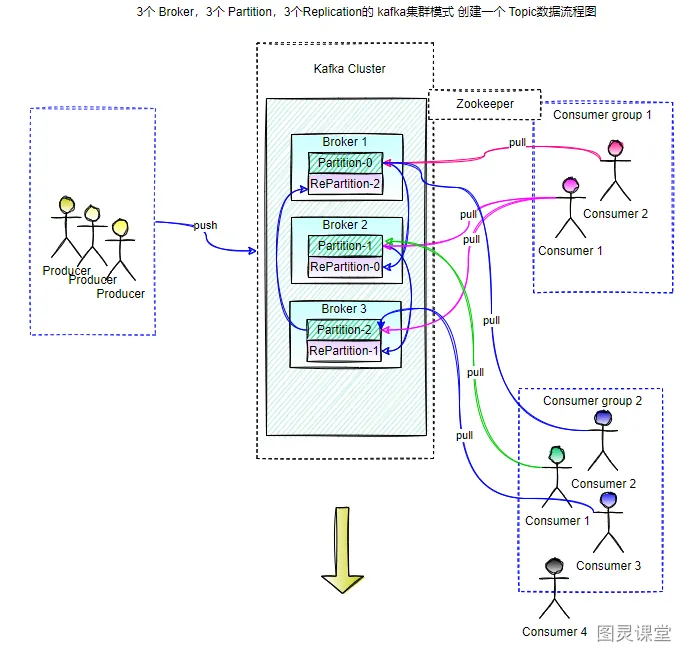
分区复制带来的好处是,提供了消息冗余。一旦首领broker失效,其他broker可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首领上。(详细过程可见下面的选举部分)
保留消息
在一定期限内保留消息是Kafka的一个重要特性,Kafka broker默认的保留策略是:要么保留一段时间(7天),要么保留一定大小(比如1个G)。到了限制,旧消息过期并删除。但是每个主题可以根据业务需求配置自己的保留策略(开发时要注意,Kafka不像Mysql之类的永久存储)。
工作流程
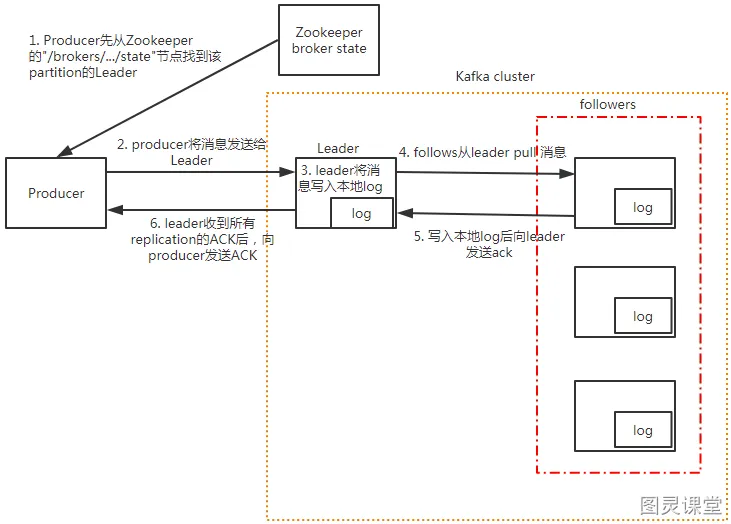
生产者发送消息流程:
- producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
- producer将消息发送给该leader
- leader将消息写入本地log
- followers从leader pull消息
- 写入本地log后向leader发送ACK
- leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit的offset)并向producer发送ACK
Tips:
- Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的
- topic是逻辑上的概念,而partition是物理上的概念,每个partition对应一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费
Kafka的数据模型与消息存储机制
消息存储结构
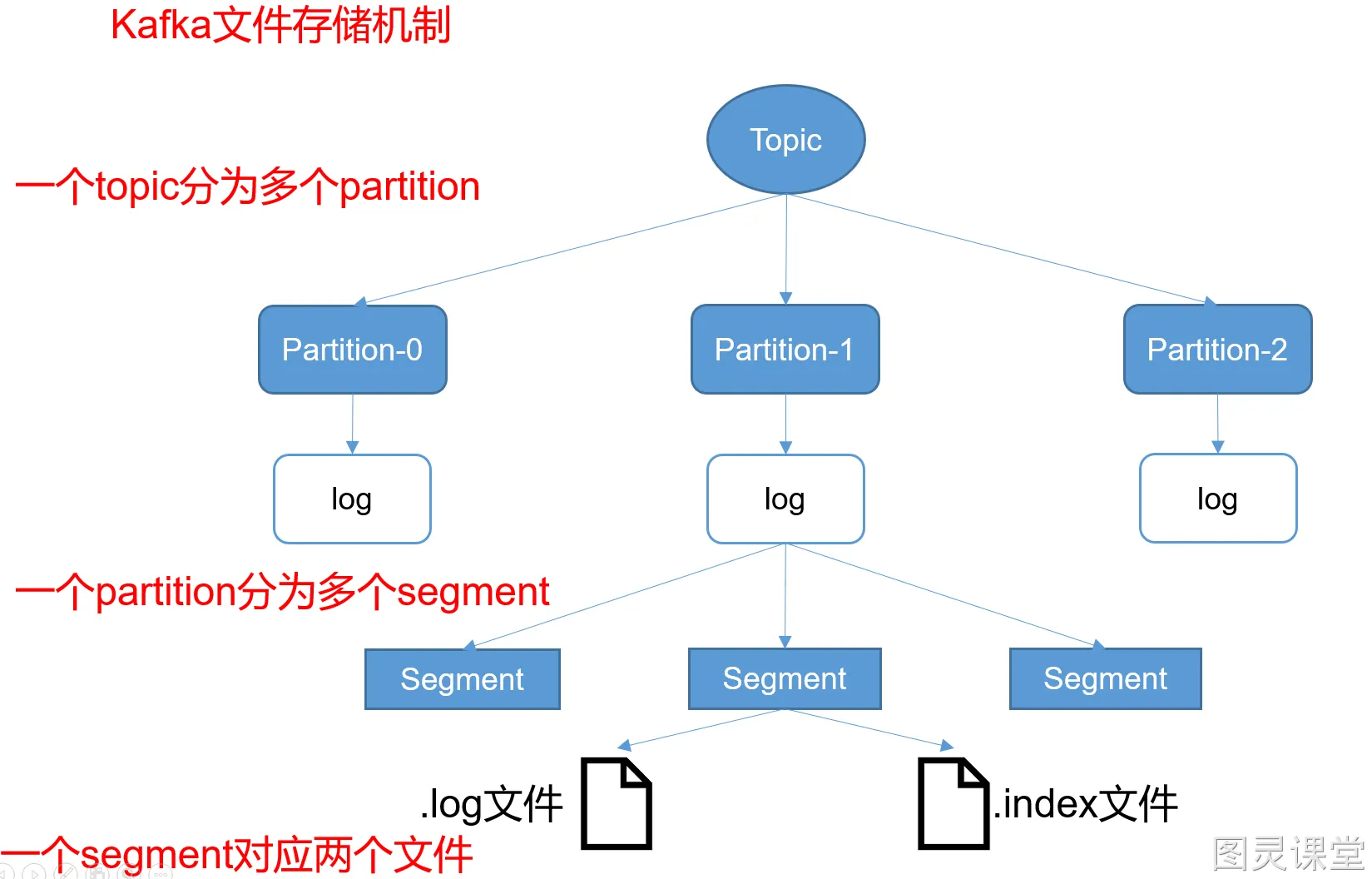
Kafka有Topic和Partition两个概念,一个Topic可以有多个Partition。在实际存储的时候,Topic + Partition对应一个文件夹,这个文件夹对应的是这个Partition的数据。
在Kafka的数据文件目录下,一个Partition对应一个唯一的文件夹。如果有4个Topic,每个Topic有5个Partition,那么一共会有4 * 5 = 20个文件夹。而在文件夹下,Kafka消息是采用Segment File的存储方式进行存储的。
Segment File的大概意思是:将大文件拆分成小文件来存储,这样一个大文件就变成了一段一段(Segment段)。这样的好处是IO加载速度快,不会有很长的IO加载时间。Kafka的消息存储就采用了这种方式。

如上图所示,在一个文件夹下的数据会根据Kafka的配置拆分成多个小文件。拆分规则可以根据文件大小拆分,也可以根据消息条数拆分,这个是Kafka的一个配置,这里不细说。
在Kafka的数据文件夹下,分为两种类型的文件:索引文件(Index File)和数据文件(Data File)。索引文件存的是消息的索引信息,帮助快速定位到某条消息。数据文件存储的是具体的消息内容。
索引文件
索引文件的命名统一为数字格式,其名称表示Kafka消息的偏移量。我们假设索引文件的数字为N,那么就代表该索引文件存储的第一条Kafka消息的偏移量为N + 1,而上个文件存储的最后一条Kafka消息的偏移量为N(因为Kafka是顺序存储的)。例如下图的368769.index索引文件,其表示文件存储的第一条Kafka消息的偏移量为368770。而368769表示的是0000.index这个索引文件的最后一条消息。所以368769.index索引文件,其存储的Kafka消息偏移量范围为368769-737337。

索引文件存储的是简单地索引数据,其格式为:「N,Position」。其中N表示索引文件里的第几条消息,而Position则表示该条消息在数据文件(Log File)中的物理偏移地址。例如下图中的「3,497」表示:索引文件里的第3条消息(即offset 368772的消息,368772 = 368769+3),其在数据文件中的物理偏移地址为497。

其他的以此类推,例如:「8,1686」表示offset为368777的Kafka消息,其在数据文件中的物理偏移地址为1686。
数据文件
数据文件的命名格式与索引文件的命名格式完全一样,这里就不再赘述了。
通过上面索引文件的分析,我们已经可以根据offset快速定位到某个数据文件了。那接着我们怎么读取到这条消息的内容呢?要读取到这条消息的内容,我们需要搞清楚数据文件的存储格式。
数据文件就是所有消息的一个列表,而每条消息都有一个固定的格式,如下图所示。

从上图可以看到Kafka消息的物理结构,其包含了Kafka消息的offset信息、Kafka消息的大小信息、版本号等等。有了这些信息之后,我们就可以正确地读取到Kafka消息的实际内容。
Kafka文件存储优势
Kafka运行时很少有大量读磁盘的操作,主要是定期批量写磁盘操作,因此操作磁盘很高效。这跟Kafka文件存储中读写message的设计是息息相关的。Kafka中读写message有如下特点:
写message:
- 消息从java堆转入page cache(即物理内存)
- 由异步线程刷盘,消息从page cache刷入磁盘
读message:
- 消息直接从page cache转入socket发送出去
- 当从page cache没有找到相应数据时,此时会产生磁盘IO,从磁盘Load消息到page cache,然后直接从socket发出去
Kafka高效文件存储设计特点:
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
- 通过索引信息可以快速定位message和确定response的最大大小
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小
Kafka副本同步机制
为保证producer发送的数据,能可靠到指定topic,topic的每个的partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送。
ACKS机制
在Kafka中,消息的ACK(Acknowledgment,确认)机制与生产者的acks配置有关。acks配置表示生产者在接收到消息后等待副本同步确认的方式,具体取值有:
acks=0:
- 意义:生产者在成功将消息发送给Kafka服务端后不等待任何确认
- 结果:生产者无法知道消息是否成功到达Kafka服务器,可能会导致消息的丢失。这种配置下,生产者不会收到任何ACK
acks=1:
- 意义:生产者在成功将消息发送给Kafka服务端后,等待该分区的首领节点(leader)确认
- 结果:生产者会收到分区首领节点的ACK。这意味着只要分区首领节点成功接收到消息,生产者就会得到确认,而不需要等待其他副本
acks=all 或 acks=-1:
- 意义:生产者在成功将消息发送给Kafka服务端后,等待所有分区副本确认
- 结果:生产者会等待分区的所有副本都成功接收到消息并确认。这是最安全的配置,因为只有当所有副本都确认接收到消息后,才认为消息被成功提交
生产者重试机制:
Kafka生产者在发送消息后,如果设置了等待服务器的确认(通过acks参数配置),会等待一定时间来收到来自服务器的确认(ack)。这个等待时间由timeout.ms参数控制,默认是10000毫秒(10秒)。
如果在等待时间内没有收到服务器的确认,生产者可以选择重试发送或者处理发送失败的逻辑。这取决于生产者的配置。通常,生产者会根据配置的重试次数和重试间隔来进行重试,以确保消息最终被成功发送。
在Kafka的生产者配置中,你可以找到以下与重试相关的配置项:
- retries:定义了生产者在发送消息时的最大重试次数
- retry.backoff.ms:定义了两次重试之间的等待时间间隔
ISR机制
Kafka根据副本同步的情况,分成了3个集合:
- AR(Assigned Replicas):包括ISR和OSR
- ISR(In-sync Replicas):和leader副本保持同步的副本集合,可以被认为是可靠的数据
- OSR(Out-Sync Replicas):和Leader副本同步失效的副本集合
当kafka副本同步机制是所有follower都同步成功才返回ack给生产者时,如果有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR-同步副本列表),意为和leader保持同步的follower集合。根据follower发来的FETCH请求中的fetch offset判断ISR中的follower完成数据同步是否成功。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。
- ISR(In-Sync Replicas):与leader保持同步的follower集合
- AR(Assigned Replicas):分区的所有副本
- ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度,当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中
- AR=ISR+OSR
ISR的伸缩
Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为"isr-expiration"和"isr-change-propagation"。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。这个周期和"replica.lag.time.max.ms"(延迟时间)参数有关。大小是这个参数一半。默认值为5000ms,当检测到ISR中有是失效的副本的时候,就会缩减ISR集合。如果某个分区的ISR集合发生变更,则会将变更后的数据记录到ZooKerper对应/brokers/topics//partition//state节点中。
Kafka选举机制
在kafka集群中有2个种leader,一种是broker的leader即controller leader,还有一种就是partition的leader。
Controller leader
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这些每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点的KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader
Partition leader
由controller leader执行:
- 从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
- 调用配置的分区选择算法选择分区的leader
kafka中的zookeeper起到什么作用
zookeeper是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用
新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,但是broker依然依赖于ZK,zookeeper在kafka中还用来选举controller和检测broker是否存活等等。
可以不用zookeeper么?
2.8.0版本以前需借助Zookeeper完成选举投票,后续版本kafka自身已集成该功能。
选举示意图
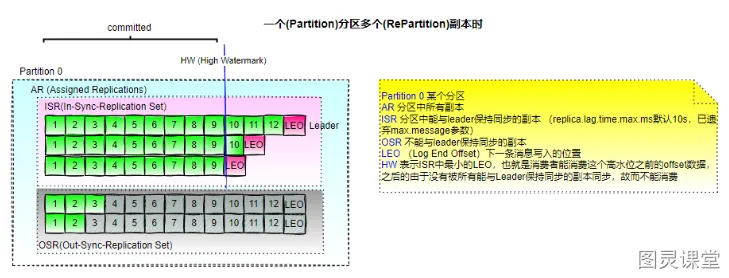
LEO表示Log End Offset下一条等待写入的消息的offset(最新的Offset+1。每一个消息都有一个offset,offset实际也是topic默认50个)
HW表示Hign Watermark ISR中最小的LEO(因为数据可能没有完全保持同步,所以Consumer最多只能消费到HW之前的位置,比如这里消费到offset5的消息,也就是说其他副本没有同步过去的消息,是不能被消费的)
follower故障: follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
选举过程:
- 故障检测:当Leader Broker发生故障或不可用时,Zookeeper会检测到该变化,并通知相关的Broker
- 选举触发:Zookeeper会触发Leader选举过程,选择一个新的Leader Broker
- 选举算法:Kafka使用一种基于Zookeeper的选举算法(如Zab协议)来选择新的Leader Broker
Kafka副本数据一致性
尽管采用acks = all但是也会出现不一致的场景,例如:
假设leader接受了producer传来的数据为8条,ISR中三台follower(broker0,broker1,broker2)开始同步数据,由于网络传输,另外两台follower同步数据的速率不同。当broker1同步了4条数据,broker2已经同步了6条数据,此时,leader-broker0突然挂掉,从ISR中选取了broker1作为主节点,此时leader-broker1同步了4条,broker2同步6,就会造成leader和follower之间数据不一致问题。
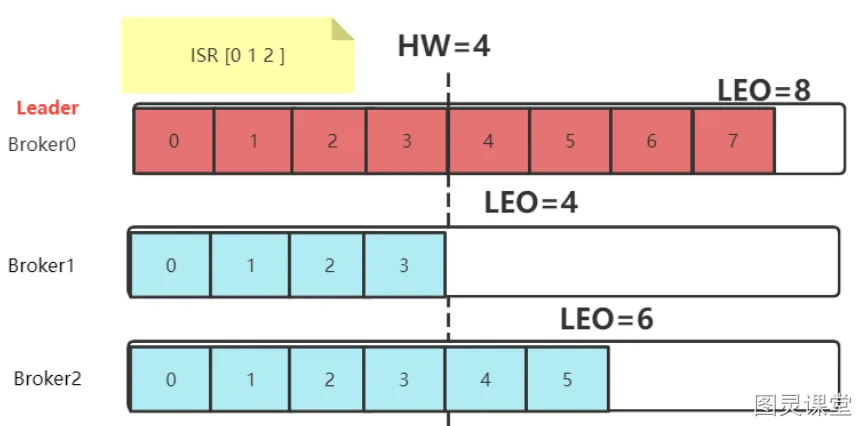
**HW(High Watermark)**俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息,对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所有消息都被认为是"已备份"的(replicated)。所有分区副本中消息偏移量最小值。
LEO(Log End Offset),即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=8,那么表示该副本保存了8条消息,位移值范围是[0, 7]。LEO的大小相当于当前日志分区中最后一条消息的offset值加1,分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费者而言只能消费HW之前的消息。
针对不同的产生原因,解决方案不同:
**当服务出现故障时:**如果是Follower发生故障,这不会影响消息写入,只不过是少了一个备份而已。处理相对简单一点。Kafka会做如下处理:
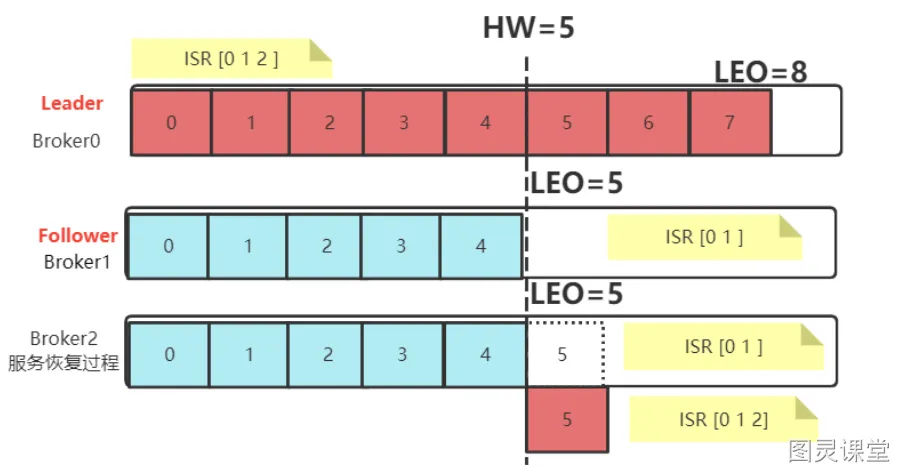
- 将故障的Follower节点临时踢出ISR集合。而其他Leader和Follower继续正常接收消息
- 出现故障的Follower节点恢复后,不会立即加入ISR集合。该Follower节点会读取本地记录的上一次的HW,将自己的日志中高于HW的部分信息全部删除掉,然后从HW开始,向Leader进行消息同步
- 等到该Follower的LEO大于等于整个Partiton的HW后,就重新加入到ISR集合中。这也就是说这个Follower的消息进度追上了Leader
如果是Leader节点出现故障,Kafka为了保证消息的一致性,处理就会相对复杂一点。
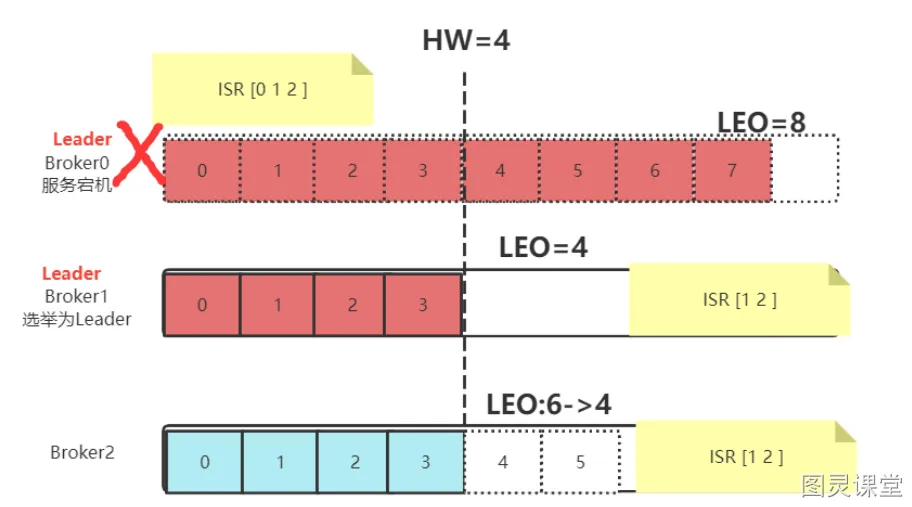
- Leader发生故障,会从ISR中进行选举,将一个原本是Follower的Partition提升为新的Leader。这时,消息有可能没有完成同步,所以新的Leader的LEO会低于之前Leader的LEO
- Kafka中的消息都只能以Leader中的备份为准。其他Follower会将各自的Log文件中高于HW的部分全部清理掉,然后从新的Leader中同步数据
- 旧的Leader恢复后,将作为Follower节点,进行数据恢复
消息顺序性
稍后完善。。。。
如何确保消息不丢失
此问题在RabbitMQ中已详细解答,这里实则类似也就是三端都需确保。
Producer端
发送数据有ACK机制:
acks = 0:由于发送后就自认为发送成功,这时如果发生网络抖动,Producer端并不会校验ACK自然也就丢了,且无法重试。
acks = 1:消息发送Leader Parition接收成功就表示发送成功,这时只要Leader Partition不Crash掉,就可以保证Leader Partition不丢数据,但是如果Leader Partition异常Crash掉了,Follower Partition还未同步完数据且没有ACK,这时就会丢数据。
acks = -1 或者 all:消息发送需要等待ISR中Leader Partition和所有的Follower Partition都确认收到消息才算发送成功,可靠性最高。当然万一有副本出问题,这就只能干等了,可以配合min.insync.replicas:设置必须确认的最小同步副本数
KafkaBroker
集群接收到数据后会将数据进行持久化存储到磁盘,为了提高吞吐量和性能,采用的是「异步批量刷盘的策略」,也就是说按照一定的消息量和间隔时间进行刷盘。首先会将数据存储到「PageCache」中,至于什么时候将Cache中的数据刷盘是由「操作系统」根据自己的策略决定或者调用fsync命令进行强制刷盘,如果此时Broker宕机Crash掉了,且选举了一个落后Leader Partition很多的Follower Partition成为新的Leader Partition,那么落后的消息数据就会丢失。所以只有配合生产者acks=-1除了leader落盘还有...
Consumer端
- 手动提交位移:关闭自动提交位移(enable.auto.commit=false),改为手动提交offset。只有在消息成功处理后才提交位移,确保消息不会因消费者故障而丢失
- 位移重置策略:通过auto.offset.reset=earliest,确保消费者在重新启动时从最早未消费的消息开始消费,避免消息丢失
- 消费者组机制:通过消费者组实现消息的负载均衡,确保消息能够被均匀分配给消费者,避免某些消费者过载导致的消息丢失
提交offset方式有commitSync()和commitAsync()两种方法
附代码:同步提交
附代码:异步提交
当然如何确保不重复消费,这里就不累赘了,可参看链接:RabbitMQ中的处理
生产者消息发送流程
整体推拉流程梳理
深入浅出之前先思考下
物流快递如何发送?:
- 先预处理快递件,(拦截器)
- 判断车队是否正常,(Producer的初始化)
- 各地区网点派发,(分区器)
- 快递封装打包(key value 序列化)
- 称重(序列化大小)
- 分拣员按地址分拣(RecordAccumulator 把消息加入Batch中)
- 集装箱装机第一次和下一个集装箱满时再来一个(tryAppend判断是否为空)
源码解读
如果直接从初始化的KafkaProducer进入send即可推送消息除了网络通信,没啥可看所以我们回顾springboot自动装配
有一个spring-boot-autoconfigure的包里面的META-INF里的spring.factories引入很多的组件。当有一个KafkaAutoConfiguration条件装配有KafkaTemplate类才会去加入相关依赖
然后发送到tianmingtest这个topic上面,当然我们可以去看下配置发送到哪些机器上面。我这里配置的三台集群上面
我们回过头看KafkaAutoConfiguration关于配置的properties
接下来send发送的方法:
kafkaTemplate.send("tianmingtest",value);
Producer的send方法可见有三个实现(首先是CloseSafeProducer是DefaultKafkaProducerFactory的)而这个工厂刚才看过是通过委派创建了KafkaProducer来发送的

可见第一个里面实际上用的也是delegate来发送的return this.delegate.send(record, callback);所以我们重点关注刚才的KafkaProducer的send方法。这里的代码跟我们的mybatis的二级缓存相似
归纳总结关键步骤:
确保可用,序列化key value放到哪个分区
这里有个面试题怎么找到topic里面的分区的呢?对应源码
- 如果指定了partition分区,就它
- 如果没有指定三个实现类实现Partitioner接口,有一个是我自己写的
实际上我们自己也可以写这个实现接口重写configure方法来实现自己的分区逻辑(自定义分区器)
然后在properties配置partitioner.class即可
注意:自定义分区应用于分布式项目需要将分区类打包放到lib包Conusumer通过partition.assignment.strategy=指定
我们回到默认的DefaultPartitioner.partition方法看看它是如何发送的。
回顾下这几个参数
因为连续问就来了:如果设置了key会怎么去发送?
所以我们第三步得记下:如果key为空会根据给的key取模也就是指定到某个分区,不为空的话会拿到可用分区去轮循到不同的分区
那么消息究竟归谁去发送的呢?
KafkaProducer构造函数可见
最终交由NetworkClient的poll方法发送此处就是网络IO模型了。Selector。。。。这里就不做深入了。(有需求,可参看网络模型)
基本流程里面到这里就基本结束了
kafka消息拦截链应用场景。分类统计修改消息异常监测数据加密字段过滤等可多个拦截链
真正发送数据的方法?如何自定义选择分区?
最终的tryAppend方法很多判断拼接
同步代码块中尝试去做一次追加操作tryAppend(),如果成功就直接返回追加的结果对象。tryAppend方法中逻辑是:
a)如果dq中有ProducerBatch则往新一个batch中追加 a.1)追加不成功,说明最新的batch空间不足,返回null。需要外层逻辑创建新的batch a.2)追加成功,返回RecordAppendResult b)dq中无producerBatch,返回null,代表没有能追加成功
第一个到达此方法的线程肯定是返回了null,因为还没有消息累积进来,也不存在ProducerBatch对象。
如果tryAppend返回null,说明没能直接在现有的batch上追加成功(也可能还没有batch),此时需要初始化新的ProducerBatch
总结一下:
- RecordAccumulator使用ProducerBatch缓存消息。每个主题分区拥有一个ProducerBatch的队列
- 当ProducerBatch队列的队尾batch不能再容纳新消息时,对其进行封箱操作,同时新建ProducerBatch放入队尾来存放新消息
- ProducerBatch对消息追加的操作都是通过MemoryRecordsBuilder进行的。消息最终被追加到MemoryRecordsBuilder中的DataOutputStream appendStream中
最后再给你们上个图吧。(图太大,看更多?)
消费者消费消息流程
整体推拉流程梳理
同样的我们也先深入浅出滴思考下
物流快递如何收件?:
- 监听物流中心(处理登记处ListenerContainer和实例化Listener)
- 分发各个快递员(将ListenerConsumer添加到Executor线程池)
- 开始按批次取件(启动线程run方法pollAndInvoke拉取消息)
- 送货上门(返回InvokeIfHaveRecords(recods))
源码解读
如果直接从初始化的KafkaConsumer进入poll即可拉取消息除了网络通信,没啥可看
所以首先我们应该已经知道消费者comsumer会在一个group里面,然后消费一个topic
怎么指定的呢@KafkaListener(topics = "tianmingtest",groupId = "testgroup")
那我们一个注解如何起效果的呢?入口类从这里开始
KafkaListenerAnnotationBeanPostProcessor
实现了BeanPostProcessor接口(讲Spring的时候还有印象没?Bean生命周期初始化Bean前后的回调的两个方法),主要开始流程在postProcessAfterInitialization后置处理器中:对象实例化之后调用(初始化回调之前的方法before先不用管)
进入processKafListener方法可见设置endpoint信息和this.processListener方法进入可见registerEndpoint方法。
进入registerEndpoint方法可见startImmediately默认false所以将信息add到List <KafakaListenerEndpointDescriptor>endpointDescriptors List集合中
那真正创建这些Listner的逻辑在哪里呢?
真正创建MessageListenerContainer的地方是在KafkaListenerEndpointRegistry中,因为最初的KafkaListenerAnnotationBeanPostProcessor类的单列实例化之后调用的方法afterSingletonsInstantiated最后
this.registrar.afterPropertiesSet();里面调用的registerAllEndpoints()
最终调用到了KafkaListenerEndpointRegistrar的registerListenerContainer
此方法
进入this.startIfNecessay实际用的参数的start方法再进入方法参数MessageListenerContainer接口的实现类AbstractMessageListenerContainer的start方法
发现是一个abstract的doStart方法,说明实现是交给它的子类去实现
我们来到它的子类KafkaMessageListenerContainer的doStart方法
接下来应该知道要到哪里了吧。肯定是run方法啊。来到listenerConsumer的run方法
这个里面我们能最终看到消费端获取消息采用的poll方式,一次性拿多条数据
进入pollAdnInvoke方法最后invokeIfHaveRecords > invokeListener(records) > 判断是否批量消费invokeBatchListener / invokeRecordListener
可以配置参数:concurrency控制listener的线程数量,并发开关可以通过batchListener = true开启配合max_poll_records_config=50多少条一次poll返回也可以配置间隔时间tnterval.ms间隔多久poll一次最多多少条

默认doInvokeWithRecords方法
是否开启事务模板invokeRecordListenerInTx和doInvokeWithRecords
默认 > doInvokeRecordListener > invokeOnMessage > doInvokeOnMessage
四种type类型的listener.提供不同的接口处理
- Simple不考虑提交偏移量和consumer对象;
- Acknowledgine需要手动提交时而不是自动提交或者spring-kafka自己实现提交方式时,需要如下接口中acknowledment的acknowlegge()方法提交偏移量
- consumer_aware类似SpringIOC的ApplicationContextAware功能,如果消费消息时,需要用consumer对象,则使用这个类型
- ACKNOWLEDGING_CONSUMER_AWARE,同时支持ACKNOWLEDGING和CONSUMER_AWARE两种类型
这些类型由接口GenericMessageListener接口具体哪个实现类来决定
最终 > onMessage返回消息
总结一下:
- 入口KafkaListenerAnnotationBeanPostProcessor,实现了BeanPostProcessor等接口,所以Bean加载完后会进入postProcessAfterInitialization方法
- 找到有@KafkaListener注解的类或者方法,并且将注解的信息封装成MethodKafkaListenerEndpoint进入processListener中registerEndpoint方法,将数据封装到KafkaListenerEndpointDescriptor,并且添加到List
- KafkaListenerAnnotationBeanPostProcessor实现了SmartInitializingSingleton,在当所有单例bean都初始化完成以后,会调用afterSingletonsInstantiated方法
- 在afterSingletonsInstantiated方法中调用registerListenerContainer方法,将消费者信息封装到listenerContainers中
- KafkaListenerEndpointRegistry类实现了SmartLifecycle接口,所以会容器启动调用start方法
- 进入AbstractMessageListenerContainer的start方法发现静态方法交给子类实现
- 进入KafkaMessageListenerContainer的doStart方法
- 实例化一个listenerConsumer,listenerConsumer实现了SchedulingAwareRunnable。SchedulingAwareRunnable继承了runnable,并将listenerConsumer添加至线程池
- 进入listenerConsumer的run方法,循环调用this.pollAndInvoke();
- pollAndInvoke中调用this.doPoll();获取信息
最后再给你们上个图吧。(图太大,看关键部分先)
理论上解下来要深入的应该是上图中的epoll了。但实际上具备上述源码已经能吊打面试官了,后续就不解读了。
有这一块诉求和能力的给你开个门吧:
Sender.run() > 注册到一个Selector Selector.send() 注册channel相当于MainReactor
实际IO操作channel.finishConnect()
然后多个处理线程KafkaChannel.setSend()相当于多个SubReactor
实际IO操作SocketChannel channel = serverSoceketChannel.accept();
真正处理的TransportLayer.addInterestOps()最后SelectionKey.interestOps();
进入nioInterestOps(key.interestOps() | SelectionKey.OP_Read或Write)相当于Work线程
实际IO操作在Channel.write / read
实际底层发送的是包装Channel的NetworkSend
Kafka消息积压问题
谁告诉你解决Kafka消息积压增加消费者数就可以了?
在Kafka的日常使用和运维过程中,消息积压几乎是每个开发者都可能遇到的问题。网上流行的一条"金句"是:消息积压了?赶紧加消费者啊!
可惜,现实往往没那么简单——只靠增加消费者实例,很多情况下并不能解决积压问题,甚至可能浪费资源。
本文带你理清Kafka消费原理,搞明白"增加消费者数"到底有没有用,什么时候有用,什么时候没用,以及真正有效的解决Kafka消息积压的方法。
一、Kafka消费并发的本质
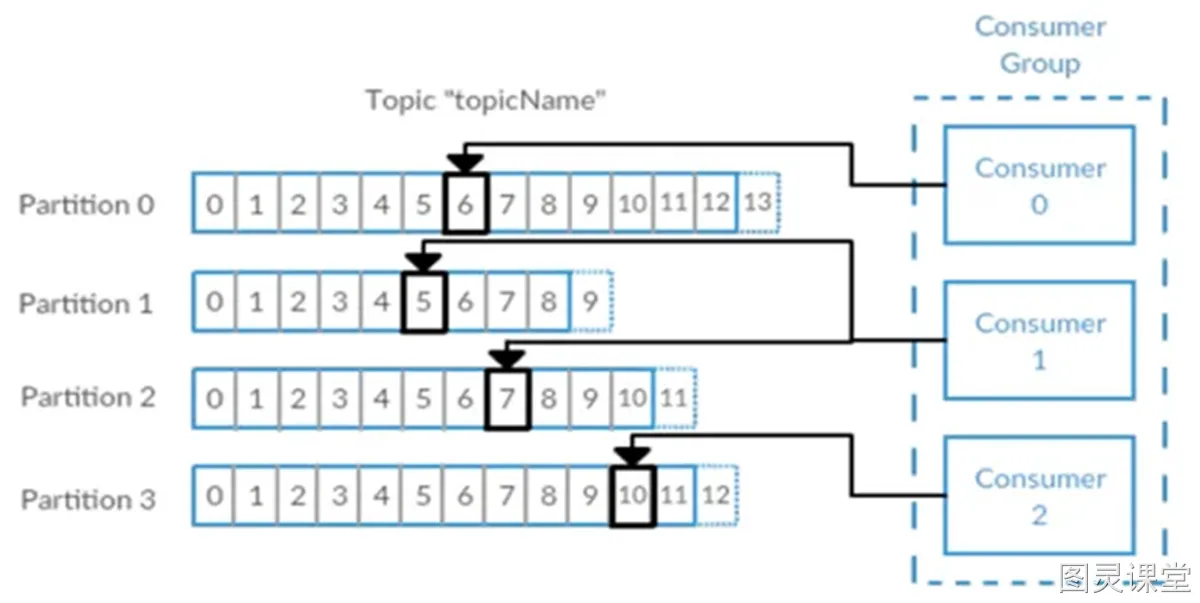
Kafka的并发消费能力,决定于两个核心指标:
- 分区数(Partition数量):Kafka主题下的分区数决定了并行消费的上限
- 消费者实例数(Consumer Instance数量):同一个消费组下,真正"在工作"的实例不能超过分区数
并发度 = min(分区数, 消费者实例数)
碰到消息积压,别急着加人头,先搞懂原理,再下药,别做无用功!