
Java基础面试题合集
1.如何优雅的避免空指针异常
空指针异常是导致java程序运行中断最常见的原因,相信每个程序猿都碰见过,也就是NullPointException,我们通常简称为NPE,本文告诉大家如何优雅避免NPE。
数据准备
package npe;
/**
* @author 百里
*/
public class User {
private String name;
private int age;
private Address address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
public User(){
}
public User(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
", address=" + address +
'}';
}
}数据准备2
package npe;
/**
* @author 百里
*/
public class Address {
private String street;
private String city;
private String country;
public Address(){
}
public Address(String street, String city, String country) {
this.street = street;
this.city = city;
this.country = country;
}
// getters and setters
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
@Override
public String toString() {
return "Address{" +
"street='" + street + '\'' +
", city='" + city + '\'' +
", country='" + country + '\'' +
'}';
}
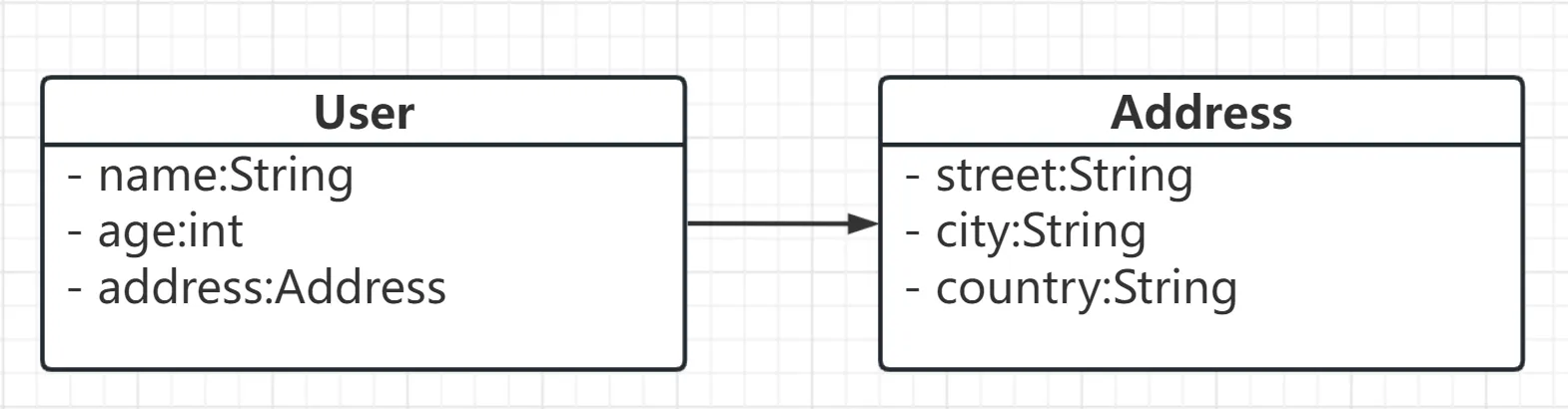
}UML类关系图:
2.实战:获取用户所在的城市
2.1.直接获取;容易出现空指针异常。
/**
* 获取人员所在的城市
* @author 百里
*/
public class BaiLiNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
String city = myUser.getAddress().getCity().trim();
System.out.println(city);
}
}2.2.使用if-else判断;避免了出现空指针的问题,但是代码结构层次嵌套多,不美观
/**
* 使用if进行判断
* @author 百里
*/
public class BaiLiSimpleNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
if (myUser != null) {
Address address = myUser.getAddress();
if (address != null) {
String city = address.getCity();
if (city != null && !"".equals(city)) {
System.out.println("使用if判断字符串:" + "一键三连");
}
}
}
}
}2.3.使用工具类美化一下if判断代码
/**
* 使用工具类
* @author 百里
*/
public class BaiLiUtilsNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address("123 Main St", " Austin ", "CA");
User myUser = new User("John Doe", 35, myAddress);
//针对对象与字符串
if (!ObjectUtils.isEmpty(myUser)) {
Address address = myUser.getAddress();
if (!ObjectUtils.isEmpty(address)) {
String city = address.getCity();
if (!StringUtils.isEmpty(city)) {
System.out.println("使用StringUtils工具类判断字符串:" + "一键三连");
}
}
}
//针对数组使用工具类
ArrayList<User> users = new ArrayList<>();
users.add(myUser);
if (!CollectionUtils.isEmpty(users)) {
System.out.println("使用CollectionUtils工具类判断数组对象:" + "一键三连");
}
}
}2.4.使用Optional解决了层次多的问题也避免了空指针的问题,当我们配合使用orElse时,会先执行orElse方法,然后执行逻辑代码,不管是否出现了空指针。
/**
* 使用Optional
* @author 百里
*/
public class BaiLiOptionalNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address();
User myUser = new User("John Doe", 35, myAddress);
System.out.println("使用Optional判断 + orElse:" +
Optional.ofNullable(myUser)
.map(User::getAddress)
.map(Address::getCity)
.map(String::trim)
.orElse(getDefaultCity())
);
}
//初始化城市
public static String getDefaultCity() {
System.out.println("初始化默认城市");
return null;
}
}2.5.使用断言处理接口入参,检查假设和前置条件是否满足,以及检查空值情况,提前捕获空指针异常并进行处理
import org.springframework.util.Assert;
/**
* 接口参数校验
* @author 百里
*/
public class BaiLiAssertNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address("123 Main St", " Austin ", "CA");
User user = new User("John Doe", 35, myAddress);
getUserCity(user);
getUserCity(null);
}
public static void getUserCity(User user){
Assert.notNull(user,"user is null");
Address address = user.getAddress();
Assert.notNull(address,"address is null");
String city = address.getCity();
System.out.println(city);
}
}2.6.使用@Nullable注解,标识变量或方法参数和返回值是否可以为 null,以便在编译期或开发工具中提示可能的 NullPointerException 风险
/**
* 使用注解 @Nullable
* @author 百里
*/
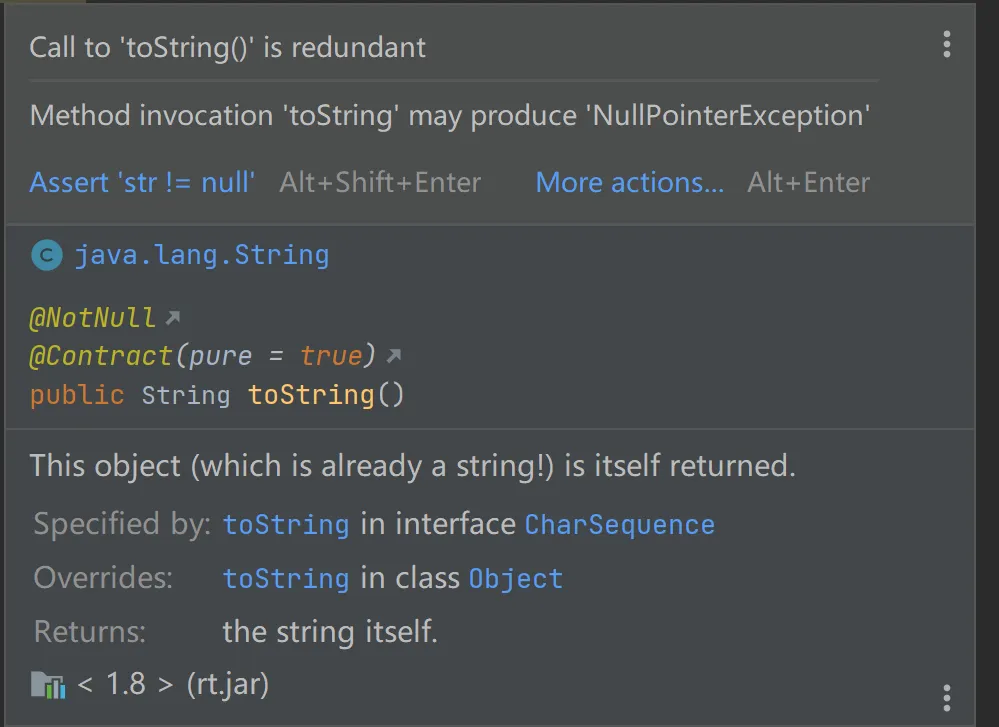
public class BaiLiNonNullDemo {
public static void printString(@Nullable String str) {
System.out.println(str.toString());
}
@Nullable
public static String getString() {
return null;
}
public static void main(String[] args) {
String str = null;
printString(str);
getString().toString();
User user = new User();
user.getAddress().getCity();
}
}
2.7.额外补充
JDK17优化了空指针异常信息(Helpful NullPointerExceptions) 通过精确描述哪个变量为空来提高JVM生成的空指针异常信息的可用性。 即,以前的空指针异常信息不会告诉你具体是哪个对象为null,当运行的语句是对一个嵌套结构的对象做连续的方法调用(如"a.getb().getc().xxx()")时,就需要进一步分析或调试才能判断出谁是null。而该特性加入以后则直接在异常信息中说明值为null的对象是哪个。
/**
* @author 百里
*/
public class BaiLiNpeDemo {
public static void main(String[] args) {
Address myAddress = new Address("123 Main St", null, "CA");
User myUser = new User("John Doe", 35, myAddress);
System.out.println(myUser.getAddress().getCity().trim());
}
}- 执行结果:
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.trim()" because the return value of "npe.Address.getCity()" is null
at npe.BaiLiNpeDemo.main(BaiLiNpeDemo.java:16)2,什么是 CopyOnWriteArrayList
1.Copy-On-Write 是什么?
Copy-On-Write它是一种在计算机科学中常见的优化技术,主要应用于需要频繁读取但很少修改的数据结构上。 简单的说就是在计算机中就是当你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了! 既然是一种优化策略,我们看一段代码:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
* @author 百里
*/
public class BaiLiIteratorTest {
private static List<String> list = new ArrayList<>();
public static void main(String[] args) {
list.add("1");
list.add("2");
list.add("3");
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
System.err.println(iter.next());
}
System.err.println(Arrays.toString(list.toArray()));
}
}上面的Demo在单线程下执行时没什么毛病,但是在多线程的环境中,就可能出异常,为什么呢? 因为多线程迭代时如果有其他线程对这个集合list进行增减元素,会抛出java.util.ConcurrentModificationException的异常。 我们以增加元素为例子,运行下面这Demo:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 并发迭代器问题示例代码
* @author 百里
*/
public class BaiLiConcurrentIteratorTest {
// 创建一个ArrayList对象
private static List<String> list = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
// 给ArrayList添加三个元素:"1"、"2"和"3"
list.add("1");
list.add("2");
list.add("3");
// 开启线程池,提交10个线程用于在list尾部添加5个元素"121"
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
for (int j = 0; j < 5; j++) {
list.add("121");
}
});
}
// 使用Iterator迭代器遍历list并输出元素值
Iterator<String> iter = list.iterator();
for (int i = 0; i < 10; i++) {
service.execute(() -> {
while (iter.hasNext()) {
System.err.println(iter.next());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
service.shutdown();
}
}这里暴露的问题是什么呢?
●多线程场景下迭代器遍历集合的读取操作和其他线程对集合进行写入操作会导致出现并发修改异常 解决方案:
●CopyOnWriteArrayList避免了多线程操作List线程不安全的问题
2.CopyOnWriteArrayList介绍
从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
- CopyOnWriteArrayList原理:
在写操作(add、remove等)时,不直接对原数据进行修改,而是先将原数据复制一份,然后在新复制的数据上执行写操作,最后将原数据引用指向新数据。这样做的好处是读操作(get、iterator等)可以不加锁,因为读取的数据始终是不变的。
接下来我们就看下源码怎么实现的。
3.CopyOnWriteArrayList简单源码解读
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;//重入锁
lock.lock();//加锁啦
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
newElements[len] = e;
setArray(newElements);//将引用指向新数组 1
return true;
} finally {
lock.unlock();//解锁啦
}
}可以看到,CopyOnWriteArrayList中的写操作都需要先获取锁,然后再将当前的元素数组复制一份,并在新复制的元素数组上执行写操作,最后将数组引用指向新数组。
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext()) //是否存在下一个元素
throw new NoSuchElementException(); //没有下一个元素,则会抛出NoSuchElementException异常
//snapshot是一个类成员变量,它是在创建迭代器时通过复制集合内容而获得的一个数组。
//cursor是另一个类成员变量,初始值为0,并在每次调用next()时自增1,表示当前返回元素的位置。
return (E) snapshot[cursor++];
}而读操作不需要加锁,直接返回当前的元素数组即可。 这种写时复制的机制保证了读操作的线程安全性,但是会牺牲一些写操作的性能,因为每次修改都需要复制一份数组。因此,适合读远多于写的场合。 所以我们将多线程Demo中的ArrayList改为CopyOnWriteArrayList,执行就不会报错啦!
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 并发迭代器问题示例代码
* @author 百里
*/
public class BaiLiConcurrentIteratorTest {
// 创建一个ArrayList对象
private static CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
public static void main(String[] args) throws InterruptedException {
// 给ArrayList添加三个元素:"1"、"2"和"3"
list.add("1");
list.add("2");
list.add("3");
// 开启线程池,提交10个线程用于在list尾部添加5个元素"121"
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
for (int j = 0; j < 5; j++) {
list.add("121");
}
});
}
// 使用Iterator迭代器遍历list并输出元素值
Iterator<String> iter = list.iterator();
for (int i = 0; i < 10; i++) {
service.execute(() -> {
while (iter.hasNext()) {
System.err.println(iter.next());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
service.shutdown();
}
}4.CopyOnWriteArrayList优缺点
优点:
1
线程安全。CopyOnWriteArrayList是线程安全的,由于写操作对原数据进行复制,因此写操作不会影响读操作,读操作可以不加锁,降低了并发冲突的概率。2
不会抛出ConcurrentModificationException异常。由于读操作遍历的是不变的数组副本,因此不会抛出ConcurrentModificationException异常。
缺点:
- 1
写操作性能较低。由于每一次写操作都需要将元素复制一份,因此写操作的性能较低。 - 2
内存占用增加。由于每次写操作都需要创建一个新的数组副本,因此内存占用会增加,特别是当集合中有大量数据时,内存占用较高。 - 3
数据一致性问题。由于读操作遍历的是不变的数组副本,因此在对数组执行写操作期间,读操作可能读取到旧的数组数据,这就涉及到数据一致性问题。
- 1
5.CopyOnWriteArrayList使用场景
读多写少。为什么?因为写的时候会复制新集合
集合不大。为什么?因为写的时候会复制新集合
实时性要求不高。为什么,因为有可能会读取到旧的集合数据
3,List操作的一些常见问题

阿里巴巴开发手册强制规约:



1. Arrays.asList转换基本类型数组
在实际的业务开发中,我们通常会进行数组转List的操作,通常我们会使用Arrays.asList来进行转换,但是在转换基本类型的数组的时候,却出现转换的结果和我们想象的不一致。
import java.util.Arrays;
import java.util.List;
/**
* Arrays.asList数组常见问题
* @author 百里
*/
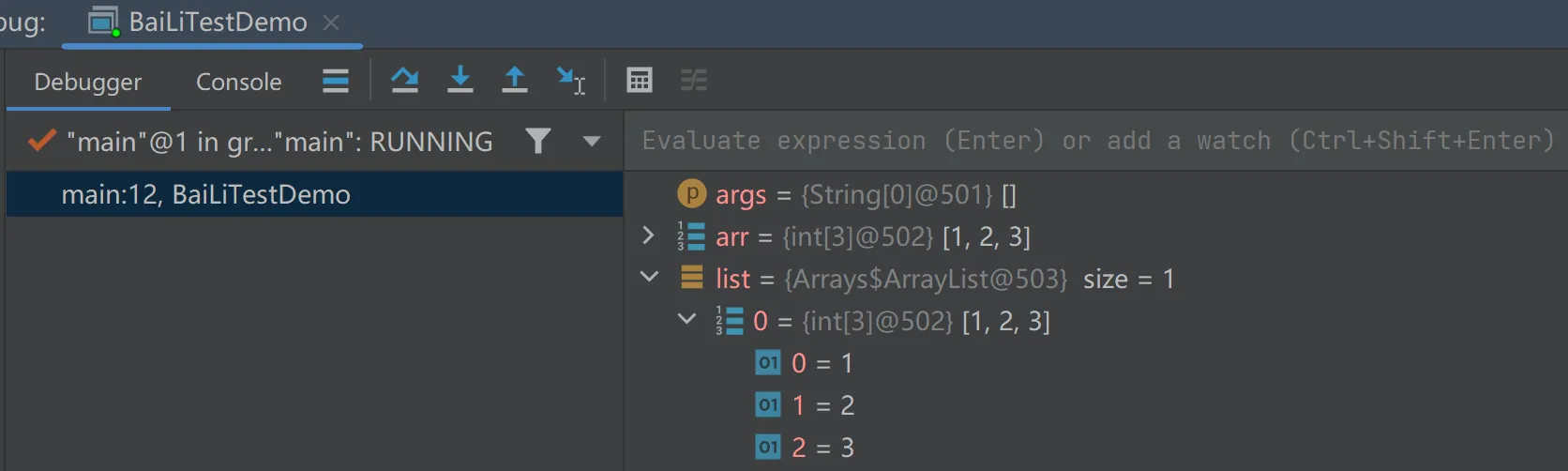
public class BaiLiTestDemo {
public static void main(String[] args) {
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
System.out.println("list.size:" + list.size());
for (int i = 0; i < list.size(); i++) {
System.out.println("循环打印:" + list.get(i));
}
}
}观察下asList的实现,可以看到是入参是使用的是泛型,所以会将{1, 2, 3}三个整数放入一个泛型列表中返回。
public static List asList(T... a) {
return new ArrayList<>(a);
}
那我们该如何解决呢?只需要在声明数组的时候,声明类型改为包装类型。
import java.util.Arrays;
import java.util.List;
/**
* Arrays.asList数组常见问题
* @author 百里
*/
public class BaiLiTestDemo {
public static void main(String[] args) {
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
System.out.println("list.size:" + list.size());//size = 3
for (int i = 0; i < list.size(); i++) {
System.out.println("循环打印:" + list.get(i));
}
}
}这就是第一个坑了,然而Arrays.asList不止这一个需要注意的问题,我们继续往下看:
2. Arrays.asList返回的List不支持增删操作
我们接着上面的demo,增加list加减的逻辑,运行demo会提示UnsupportedOperationException:
import java.util.Arrays;
import java.util.List;
/**
* Arrays.asList数组常见问题
* @author 百里
*/
public class BaiLiTestDemo {
public static void main(String[] args) {
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
System.out.println("list.size:" + list.size());
list.add(4);
}
}为什么会这样?我们看下asList的实现,它返回的ArrayList是Arrays的内部类,而不是我们通常使用的java.util.ArrayList:
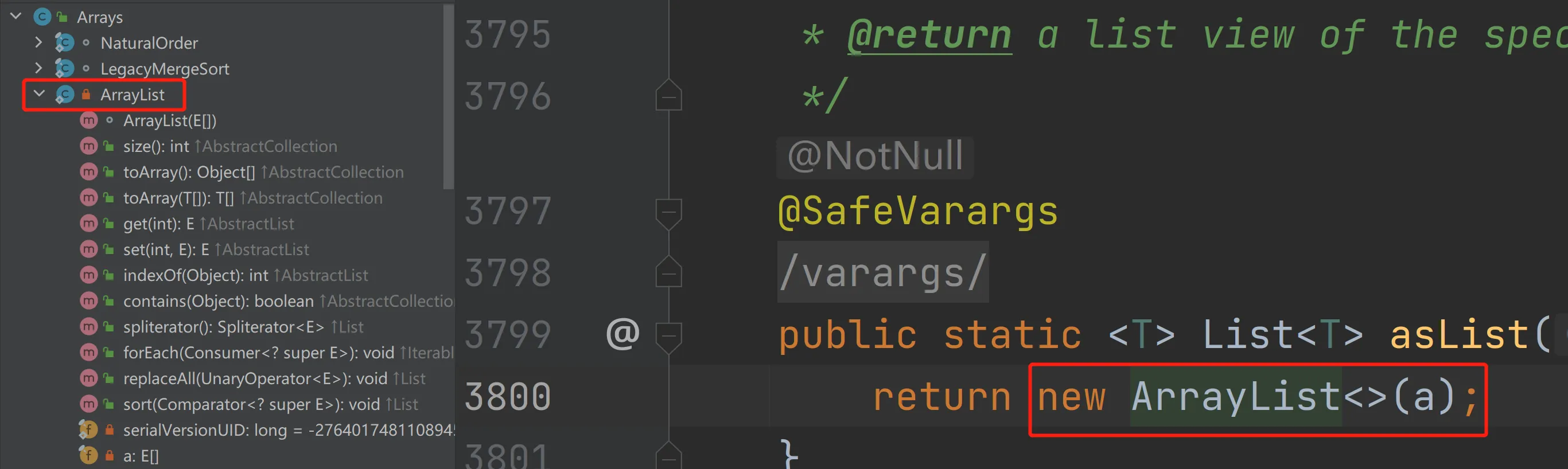
可以看到内部类中的ArrayList没有add()与remove(),那我们怎么可以使用增减方法呢,继续往下看:
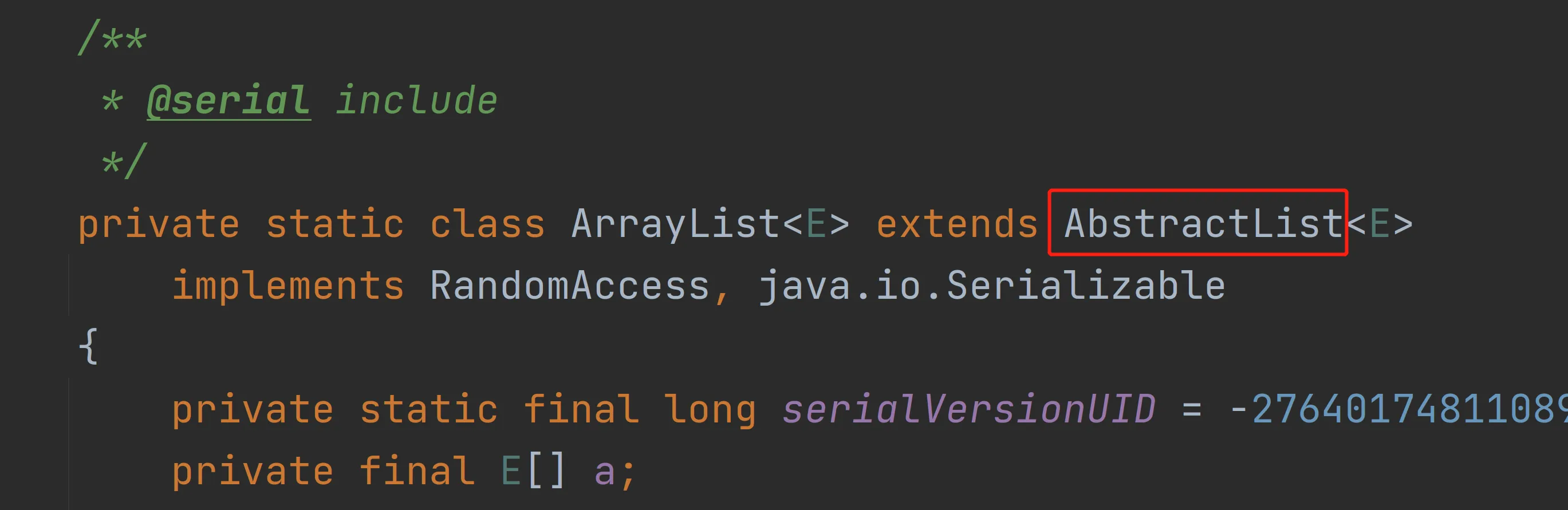
可以看到ArrayList继承了AbstractList类,我们观察AbstractList类的add()与remove():
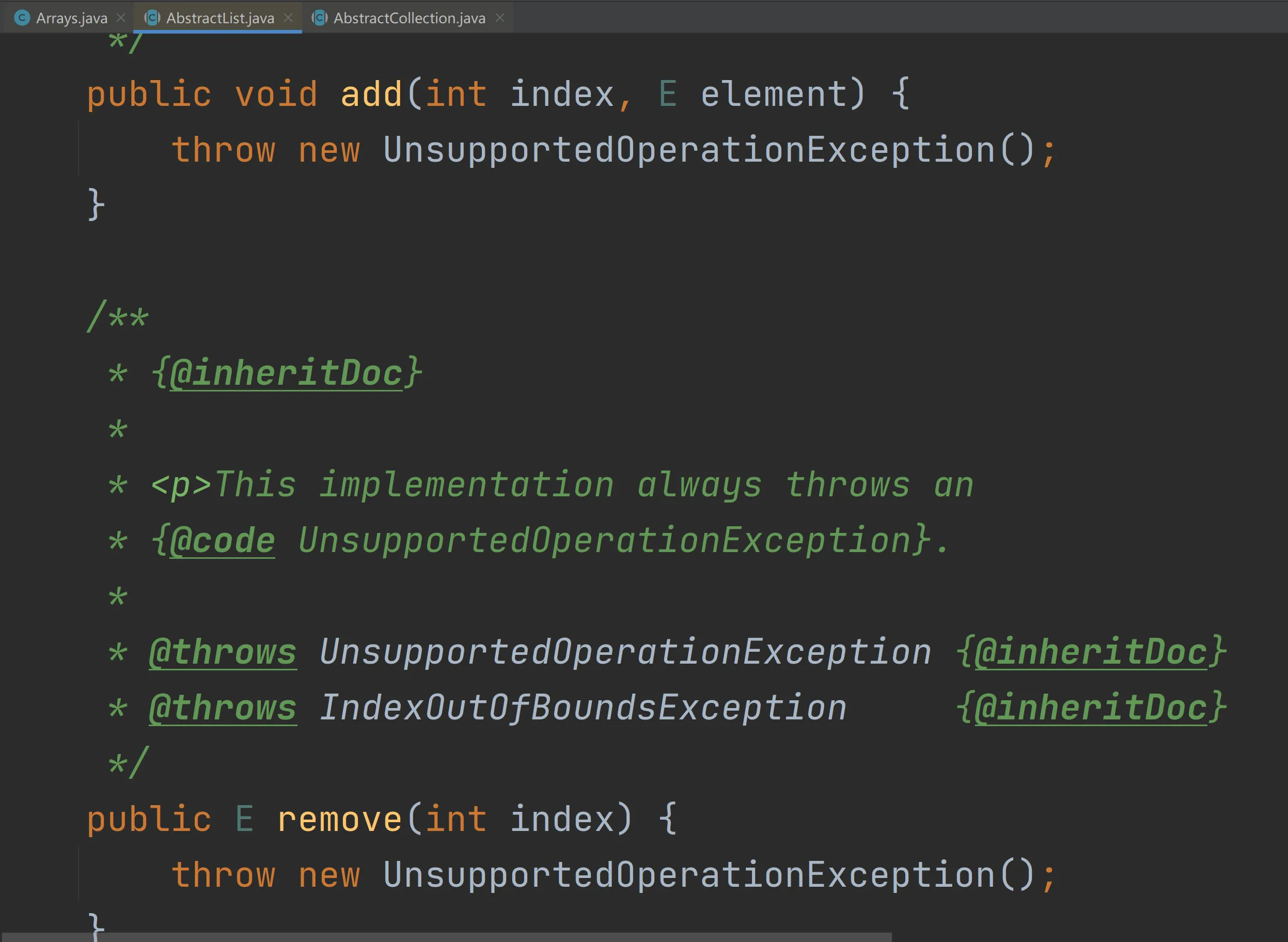
现在是不是就理解Arrays.asList返回的List不支持增删操作了。
3. 对原始数组的修改会影响到我们获得的那个List
基于第一个demo我们继续改造,修改原arr[0]=10,这个时候打印Arrays.asList返回的list值也发生了改变:
import java.util.Arrays;
import java.util.List;
/**
* Arrays.asList数组常见问题
* @author 百里
*/
public class BaiLiTestDemo {
public static void main(String[] args) {
Integer[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
System.out.println("list.size:" + list.size());
arr[0] = 10;//修改原数组
for (int i = 0; i < list.size(); i++) {
System.out.println("循环打印:" + list.get(i));
}
}
}为什么呢?观察ArrayList的实现,可以知道asList创建了 ArrayList,但它直接引用原本的数据组对象。所以只要原本的数组对象一发生变化,List也跟着变化。
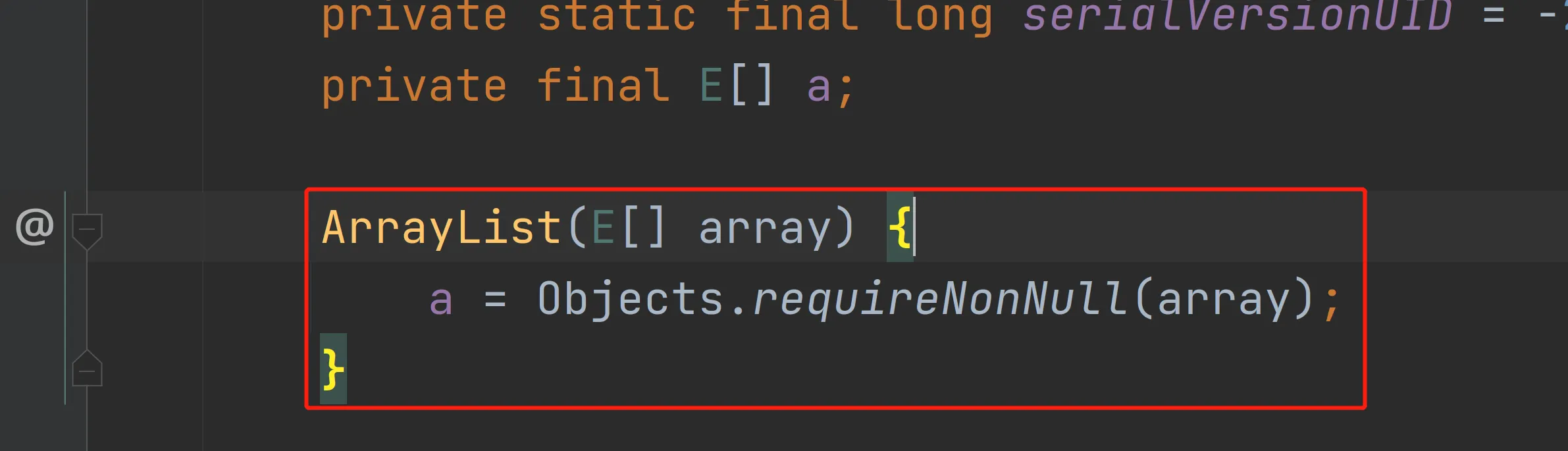
解决方案:new一个新的ArrayList装Arrays.asList返回数据。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* Arrays.asList数组常见问题
* @author 百里
*/
public class BaiLiTestDemo {
public static void main(String[] args) {
Integer[] arr = {1, 2, 3};
List list = new ArrayList<>(Arrays.asList(arr));
arr[0] = 10;
for (int i = 0; i < list.size(); i++) {
System.out.println("循环打印:" + list.get(i));
}
}
}4. ArrayList.subList强转ArrayList导致异常
当使用ArrayList.subList的返回list强转ArrayList时,会出现java.lang.ClassCastException,看以下代码:
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList.subList常见问题
* @author 百里
*/
public class BaiLiArrayListDemo {
public static void main(String[] args) {
List<String> names = new ArrayList<String>() {{
add("one");
add("two");
add("three");
}};
ArrayList strings = (ArrayList) names.subList(0, 1);
System.out.println(strings);
}
}Exception in thread "main" java.lang.ClassCastException: java.util.ArrayList$SubList cannot be cast to java.util.ArrayList
at BaiLiArrayListDemo.main(BaiLiArrayListDemo.java:15)同样的,我们看下sublist的实现:
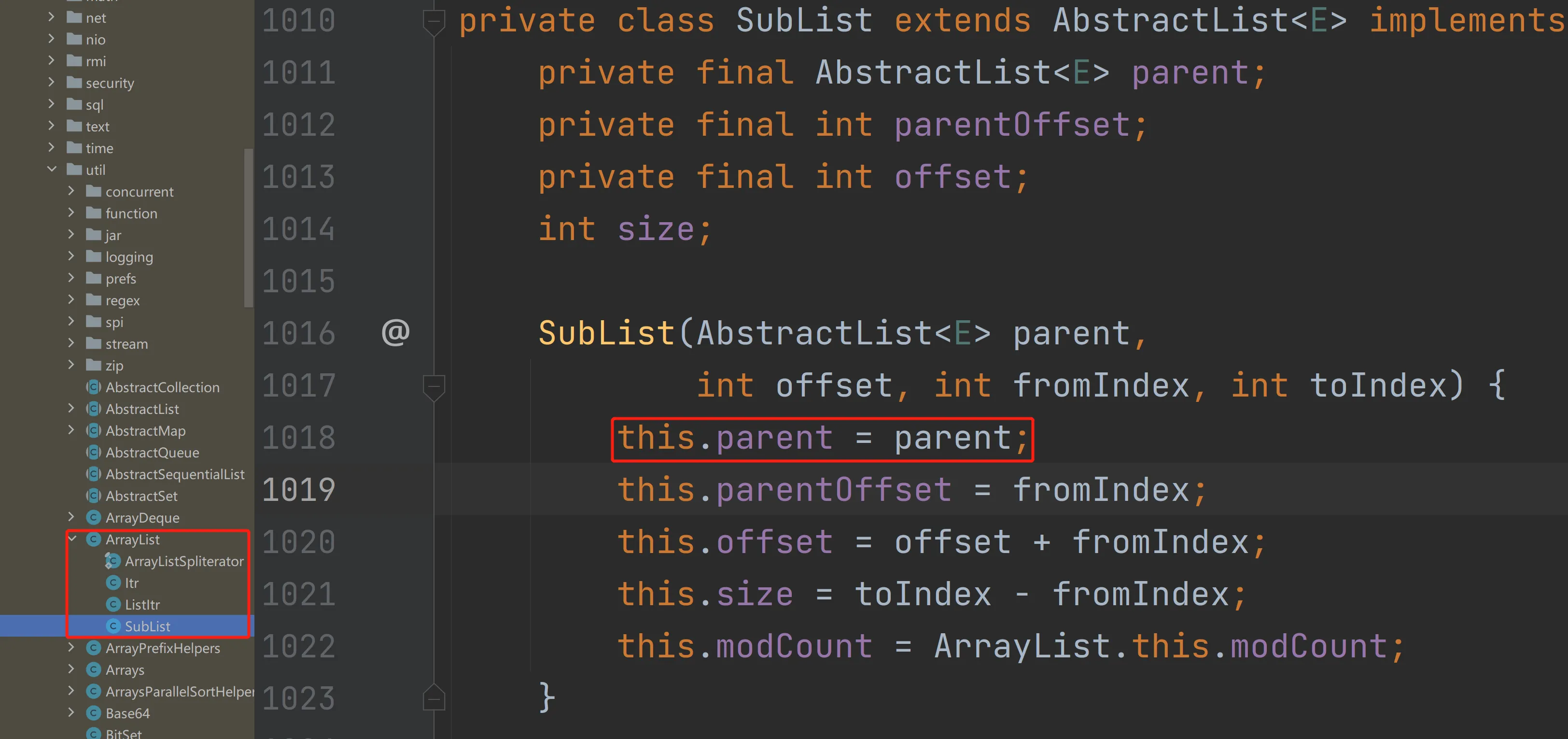
可以看到SubList()实际上没有创建一个新的List,而是直接引用了原来的List,指定了元素的范围。并且返回的是一个内部类实现的SubList对象,该对象只是原始ArrayList的一个引用,而不是一个全新的ArrayList,因此无法直接将其强制转换为ArrayList类型。 由于是引用的原List,因此也会存在asList的问题,也就是针对subList进行增减数据,会影响原List的值。
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList.subList常见问题
* @author 百里
*/
public class BaiLiArrayListDemo {
public static void main(String[] args) {
List<String> names = new ArrayList<String>() {{
add("one");
add("two");
add("three");
}};
List strings = names.subList(0, 1);
strings.add(0,"four");
System.out.println(strings);//[four, one]
System.out.println(names);//[four, one, two, three]
}
}需要注意修改原List-names的值会出导致strings的遍历、增加、删除产生ConcurrentModificationException异常。
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList.subList常见问题
* @author 百里
*/
public class BaiLiArrayListDemo {
public static void main(String[] args) {
List<String> names = new ArrayList<String>() {{
add("one");
add("two");
add("three");
}};
List strings = names.subList(0, 1);
names.add("four");
System.out.println(strings);
System.out.println(names);
}
}Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1231)
at java.util.ArrayList$SubList.listIterator(ArrayList.java:1091)
at java.util.AbstractList.listIterator(AbstractList.java:299)
at java.util.ArrayList$SubList.iterator(ArrayList.java:1087)
at java.util.AbstractCollection.toString(AbstractCollection.java:454)
at java.lang.String.valueOf(String.java:2994)
at java.io.PrintStream.println(PrintStream.java:821)
at BaiLiArrayListDemo.main(BaiLiArrayListDemo.java:17)上面问题的解决方案跟asList同样,直接new一个新的ArrayList装Arrays.subList返回数据就可以了。
import java.util.ArrayList;
import java.util.List;
/**
* ArrayList.subList常见问题
* @author 百里
*/
public class BaiLiArrayListDemo {
public static void main(String[] args) {
List<String> names = new ArrayList<String>() {{
add("one");
add("two");
add("three");
}};
List strings = new ArrayList<>(names.subList(0, 1));
strings.add("four");
System.out.println(strings);//[one, four]
System.out.println(names);//[one, two, three]
}
}5. ArrayList中的subList切片造成OOM
subList所产生的List,其实是对原来List对象的引用,这个产生的List只是原来List对象的视图,也就是说虽然值切片获取了一小段数据,但是原来的List对象却得不到回收,如果这个原来的对象很大,就会出现OOM的情况。我们将VM参数调小:-Xms20m -Xmx40m
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
/**
* ArrayList.subList常见问题
* @author 百里
*/
public class BaiLiArrayListDemo {
public static void main(String[] args) {
List data = new ArrayList<>();
IntStream.range(0, 1000).forEach(i ->{
List<Integer> collect =
IntStream.range(0, 100000).boxed().
collect(Collectors.toList());
data.add(collect.subList(0, 1));
});
}
}出现OOM的原因:原数组无法被回收,会一直在内存中。 解决方案:new一个新的ArrayList接收subList返回。
6.Copy-On-Write 是什么?
Copy-On-Write它是一种在计算机科学中常见的优化技术,主要应用于需要频繁读取但很少修改的数据结构上。 简单的说就是在计算机中就是当你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了! 既然是一种优化策略,我们看一段代码:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
* @author 百里
*/
public class BaiLiIteratorTest {
private static List<String> list = new ArrayList<>();
public static void main(String[] args) {
list.add("1");
list.add("2");
list.add("3");
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
System.err.println(iter.next());
}
System.err.println(Arrays.toString(list.toArray()));
}
}上面的Demo在单线程下执行时没什么毛病,但是在多线程的环境中,就可能出异常,为什么呢? 因为多线程迭代时如果有其他线程对这个集合list进行增减元素,会抛出java.util.ConcurrentModificationException的异常。 我们以增加元素为例子,运行下面这Demo:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 并发迭代器问题示例代码
* @author 百里
*/
public class BaiLiConcurrentIteratorTest {
// 创建一个ArrayList对象
private static List<String> list = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
// 给ArrayList添加三个元素:"1"、"2"和"3"
list.add("1");
list.add("2");
list.add("3");
// 开启线程池,提交10个线程用于在list尾部添加5个元素"121"
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
for (int j = 0; j < 5; j++) {
list.add("121");
}
});
}
// 使用Iterator迭代器遍历list并输出元素值
Iterator<String> iter = list.iterator();
for (int i = 0; i < 10; i++) {
service.execute(() -> {
while (iter.hasNext()) {
System.err.println(iter.next());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
service.shutdown();
}
}这里暴露的问题是什么呢?
- 多线程场景下迭代器遍历集合的读取操作和其他线程对集合进行写入操作会导致出现并发修改异常
解决方案:
- CopyOnWriteArrayList避免了多线程操作List线程不安全的问题
7.CopyOnWriteArrayList介绍
从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWriteArrayList原理:在写操作(add、remove等)时,不直接对原数据进行修改,而是先将原数据复制一份,然后在新复制的数据上执行写操作,最后将原数据引用指向新数据。这样做的好处是读操作(get、iterator等)可以不加锁,因为读取的数据始终是不变的。 接下来我们就看下源码怎么实现的。
8.CopyOnWriteArrayList简单源码解读
add()方法源码:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;//重入锁
lock.lock();//加锁啦
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
newElements[len] = e;
setArray(newElements);//将引用指向新数组 1
return true;
} finally {
lock.unlock();//解锁啦
}
}可以看到,CopyOnWriteArrayList中的写操作都需要先获取锁,然后再将当前的元素数组复制一份,并在新复制的元素数组上执行写操作,最后将数组引用指向新数组。
@SuppressWarnings("unchecked")
public E next() {
if (! hasNext()) //是否存在下一个元素
throw new NoSuchElementException(); //没有下一个元素,则会抛出NoSuchElementException异常
//snapshot是一个类成员变量,它是在创建迭代器时通过复制集合内容而获得的一个数组。
//cursor是另一个类成员变量,初始值为0,并在每次调用next()时自增1,表示当前返回元素的位置。
return (E) snapshot[cursor++];
}而读操作不需要加锁,直接返回当前的元素数组即可。 这种写时复制的机制保证了读操作的线程安全性,但是会牺牲一些写操作的性能,因为每次修改都需要复制一份数组。因此,适合读远多于写的场合。 所以我们将多线程Demo中的ArrayList改为CopyOnWriteArrayList,执行就不会报错啦!
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 并发迭代器问题示例代码
* @author 百里
*/
public class BaiLiConcurrentIteratorTest {
// 创建一个ArrayList对象
private static CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
public static void main(String[] args) throws InterruptedException {
// 给ArrayList添加三个元素:"1"、"2"和"3"
list.add("1");
list.add("2");
list.add("3");
// 开启线程池,提交10个线程用于在list尾部添加5个元素"121"
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
for (int j = 0; j < 5; j++) {
list.add("121");
}
});
}
// 使用Iterator迭代器遍历list并输出元素值
Iterator<String> iter = list.iterator();
for (int i = 0; i < 10; i++) {
service.execute(() -> {
while (iter.hasNext()) {
System.err.println(iter.next());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
service.shutdown();
}
}9.CopyOnWriteArrayList优缺点
- 优点:
1
线程安全。CopyOnWriteArrayList是线程安全的,由于写操作对原数据进行复制,因此写操作不会影响读操作,读操作可以不加锁,降低了并发冲突的概率。2
不会抛出ConcurrentModificationException异常。由于读操作遍历的是不变的数组副本,因此不会抛出ConcurrentModificationException异常。
- 缺点:
1
写操作性能较低。由于每一次写操作都需要将元素复制一份,因此写操作的性能较低。2
内存占用增加。由于每次写操作都需要创建一个新的数组副本,因此内存占用会增加,特别是当集合中有大量数据时,内存占用较高。3
数据一致性问题。由于读操作遍历的是不变的数组副本,因此在对数组执行写操作期间,读操作可能读取到旧的数组数据,这就涉及到数据一致性问题。
10.CopyOnWriteArrayList使用场景
读多写少。为什么?因为写的时候会复制新集合
集合不大。为什么?因为写的时候会复制新集合
实时性要求不高。为什么,因为有可能会读取到旧的集合数据
4如何优雅的删除HashMap元素
图灵学院-百里
1.数据准备
public Map<String, String> initMap = new HashMap<String, String>() {{
put("user1", "刘零");
put("user2", "郑一");
put("user3", "吴二");
put("user4", "张三");
put("user5", "李四");
put("user6", "王五");
put("user7", "钱六");
put("user8", "孙七");
}};2.删除方式
2.1.使用增强 for 循环删除
/**
* 使用 for 循环删除
*/
public void remove1() {
Set<Map.Entry<String, String>> entries = new CopyOnWriteArraySet<>(initMap.entrySet());
for (Map.Entry<String, String> entry : entries) {
if ("王五".equals(entry.getValue())) {
initMap.remove(entry.getKey());
}
}
System.out.println(initMap);
}输出结果: {user1=刘零, user2=郑一, user7=钱六, user8=孙七, user5=李四, user3=吴二, user4=张三}
通过HashMap的entrySet方法获取元素集合,然后再进行循环遍历,判断value值是否为需要删除的元素,再移除对应的Key。 需要注意增强的 for 循环底层使用的迭代器 Iterator,而 HashMap 是 fail-fast 原则的错误机制,所以遍历时删除元素会出现 java.util.ConcurrentModificationException 并发修改异常。我们可以使用CopyOnWriteArraySet封装一层避免出现并发修改异常。
- fail-fast:为了将错误或异常情况尽早暴露出来,避免潜在的问题在后续代码中蔓延,提高系统的稳定性和可靠性。
2.2.使用 forEach 循环删除
/**
* 使用 forEach 循环删除
*/
public void remove2() {
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(initMap);
map.forEach((k, v) -> {
if ("王五".equals(v)) {
map.remove(k);
}
});
System.out.println(map);
}输出结果: {user1=刘零, user2=郑一, user7=钱六, user8=孙七, user5=李四, user3=吴二, user4=张三} 通过HashMap的forEach方法循环删除目标元素,同样的使用了ConcurrentHashMap封装避免出现并发修改异常。
2.3.使用 Iterator 迭代器删除
/**
* 使用 Iterator 迭代器删除
*/
@Test
public void remove3() {
ConcurrentHashMap<String, String> resultMap = new ConcurrentHashMap<>();
Iterator<Map.Entry<String, String>> iterator
= new ConcurrentHashMap<>(initMap).entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
if ("王五".equals(entry.getValue())) {
iterator.remove();
}else {
resultMap.put(entry.getKey(),entry.getValue());
}
}
System.out.println(resultMap);
}输出结果: {user1=刘零, user2=郑一, user7=钱六, user8=孙七, user5=李四, user3=吴二, user4=张三} 通过Iterator迭代删除元素不会出现并发修改异常,但由于HashMap是线程不安全的,这时如果多个线程同时修改HashMap数据也会出现并发修改异常 ,日常使用可以先用ConcurrentHashMap封装。
2.4.使用 removeIf 删除(推荐使用)
/**
* 使用 removeIf 删除
*/
public void remove4() {
initMap.entrySet().removeIf(entry -> "王五".equals(entry.getValue()));
System.out.println(initMap);
}输出结果: {user1=刘零, user2=郑一, user7=钱六, user8=孙七, user5=李四, user3=吴二, user4=张三} 通过entrySet获取元素然后使用removeIf方法删除目标数据;而removeIf的底层是通过Iterator迭代器实现的。所以也存在第三种方法同样的问题。
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}2.5.使用 Stream 删除(推荐使用)
/**
* 使用 Stream 删除
*/
public void remove5() {
Map<String, String> map = initMap.entrySet().stream()
.filter(entry -> !"王五".equals(entry.getValue()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(map);
}输出结果: {user1=刘零, user2=郑一, user7=钱六, user8=孙七, user5=李四, user3=吴二, user4=张三} 通过Stream 的 filter 方法进行过滤,然后生成一个新的map。这种方式“一行代码“就能够实现删除的动作,并且没有并发问题。
5使用BigDecimal 一定需要注意的几个坑
5.1BigDecimal概述
BigDecimal 是 Java 中的一个类,用于精确表示和操作任意精度的十进制数。它提供了高精度的数值计算,并且可以避免浮点数计算中常见的精度丢失问题。 它提供了大量的方法来支持基本的数学运算,如加法、减法、乘法、除法等。它还支持比较操作和取整操作,可以设置小数位数、舍入模式等。此外,BigDecimal 还提供了一些其他功能,如转换为科学计数法、格式化输出、判断是否是整数等。
适用场景:需要处理精确计算或防止浮点数计算精度丢失的场景。
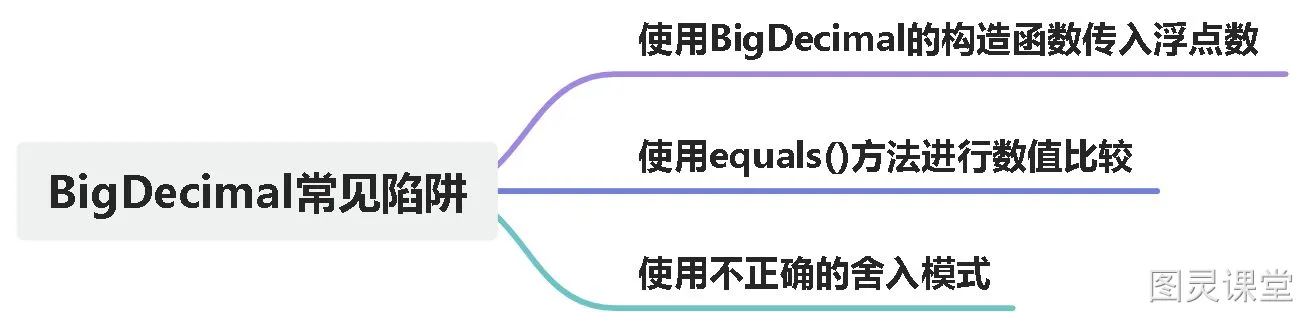
BigDecimal常见陷阱
1.使用BigDecimal的构造函数传入浮点数
其实这个问题我们在使用Float、Double等浮点类型进行计算时,也会经常遇到,比如说下面这个代码
@Test
public void bigDecimalDemo1() {
float float1 = 1;
float float2 = 0.9f;
System.out.println(float1 - float2);
}输出结果是多少呢?0.1?不是,输出结果是0.100000024。因为 0.9 无法被精确表示为有限位数的二进制小数。在转换为二进制时可能会产生近似值。因此,在进行减法运算时,实际上是对近似值进行计算,而不是对准确的 0.9 进行计算。这导致了精度丢失,最终的计算结果也是一个近似值。因此,输出结果不是准确的 0.1,而是一个近似值。 小伙伴肯定能想到使用BigDecimal来避免这个问题,这时候第一个需要避免的陷阱就来了。看以下代码:
@Test
public void bigDecimalDemo2(){
BigDecimal bigDecimal1 = new BigDecimal(0.01);
BigDecimal bigDecimal2 = BigDecimal.valueOf(0.01);
System.out.println("bigDecimal1 = " + bigDecimal1);
System.out.println("bigDecimal2 = " + bigDecimal2);
}输出结果如下:
bigDecimal1 = 0.01000000000000000020816681711721685132943093776702880859375
bigDecimal2 = 0.01
观察输出结果我们可以知道,使用BigDecimal时同样会有精度的问题。所以我们在创建BigDecimal对象时,有初始值使用BigDecimal.valueOf()的方式,可以避免出现精度问题。
为什么会出现差异?
在使用new BigDecimal()实际上是将 0.01 转换为二进制近似值,并将其存储为 BigDecimal 对象。因此,结果中存在微小的误差,即输出结果为0.01000000000000000020816681711721685132943093776702880859375。
而BigDecimal.valueOf()不同,其内部是先将double转为String,因此不存在精度问题。
public static BigDecimal valueOf(double val) {
// Reminder: a zero double returns '0.0', so we cannot fastpath
// to use the constant ZERO. This might be important enough to
// justify a factory approach, a cache, or a few private
// constants, later.
return new BigDecimal(Double.toString(val));
}TIPS:
1使用整数或长整数作为参数构造:
BigDecimal(int val):使用一个 int 类型的整数值创建 BigDecimal。
BigDecimal(long val):使用一个 long 类型的整数值创建 BigDecimal。
2使用字符串作为参数构造:
BigDecimal(String val):使用一个字符串表示的数值创建 BigDecimal。该字符串可以包含整数部分、小数部分和指数部分。
3使用双精度浮点数作为参数构造:
BigDecimal(double val):使用一个 double 类型的浮点数值创建 BigDecimal。注意,由于浮点数精度可能丢失,建议使用字符串或其他方法构造 BigDecimal,以避免精度损失问题。
4使用基于 BigInteger 的构造方法:
BigDecimal(BigInteger val):使用一个 BigInteger 对象来创建 BigDecimal。2.使用equals()方法进行数值比较
日常项目我们是如何进行BigDecimal数值比较呢?使用equals方法还是compareTo方法?如果使用的是equals方法,那就需要注意啦。看一下示例:
@Test
public void bigDecimalDemo3(){
BigDecimal bigDecimal1 = new BigDecimal("0.01");
BigDecimal bigDecimal2 = new BigDecimal("0.010");
System.out.println(bigDecimal1.equals(bigDecimal2));
System.out.println(bigDecimal1.compareTo(bigDecimal2));
}输出结果如下:
false
0观察结果可以知道使用equals比较结果是不相等的;compareTo的结果为0代表两个数相等;
- compareTo实现了Comparable接口,比较的是值的大小,返回的值为-1-小于,0-等于,1-大于。
为什么equals返回的是false?
public boolean equals(Object x) {
if (!(x instanceof BigDecimal))
return false;
BigDecimal xDec = (BigDecimal) x;
if (x == this)
return true;
if (scale != xDec.scale)
return false;
long s = this.intCompact;
long xs = xDec.intCompact;
if (s != INFLATED) {
if (xs == INFLATED)
xs = compactValFor(xDec.intVal);
return xs == s;
} else if (xs != INFLATED)
return xs == compactValFor(this.intVal);
return this.inflated().equals(xDec.inflated());
}我们观察equals的实现逻辑可以知道,BigDecimal重写了equals方法,重写后的关键代码:
if (scale != xDec.scale)
return false;也就是会比较两个数值的精度,精度不同返回false。
3.使用不正确的舍入模式
使用BigDecimal进行运算时,一定要正确的使用舍入模式,避免舍入误差引起的问题,并且有时候出现结果是无限小数,程序会抛出异常,比如说:
@Test
public void bigDecimalDemo4(){
BigDecimal bigDecimal1 = new BigDecimal("1.00");
BigDecimal bigDecimal2 = new BigDecimal("3.00");
BigDecimal bigDecimal3 = bigDecimal1.divide(bigDecimal2);
System.out.println(bigDecimal3);
}输出结果如下:
java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result.简单的来说,如果在除法运算过程中,其结果是一个无限小数,而操作的结果预期是一个精确的数字,那么将会抛出ArithmeticException异常。 此时,我们只要正确指定结果精度即可:
@Test
public void bigDecimalDemo4(){
BigDecimal bigDecimal1 = new BigDecimal("1.00");
BigDecimal bigDecimal2 = new BigDecimal("3.00");
BigDecimal bigDecimal3 = bigDecimal1.divide(bigDecimal2, 2, RoundingMode.HALF_UP);
System.out.println(bigDecimal3);
}输出结果如下:
0.33TIPS:
RoundingMode.UP:向远离零的方向舍入
RoundingMode.DOWN:向靠近零的方向舍入
RoundingMode.CEILING:向正无穷方向舍入
RoundingMode.FLOOR:向负无穷方向舍入
RoundingMode.HALF_UP:四舍五入,如果舍弃部分大于等于 0.5
RoundingMode.HALF_DOWN:四舍五入,如果舍弃部分大于 0.5
RoundingMode.HALF_EVEN:银行家舍入法,遵循 IEEE 754 标准总结:
尽量使用字符串而非浮点类型来构造 BigDecimal 对象,以避免浮点数转换精度问题。
如果无法避免使用浮点类型,则可使用 BigDecimal.valueOf 方法来构造初始化值,以确保精确表示。
比较两个 BigDecimal 值的大小时,使用 compareTo 方法。如果需要严格限制精度的比较,可以考虑使用 equals 方法。
在进行 BigDecimal 运算前,明确指定精度和舍入模式。使用 setScale 方法设置精度,使用 setRoundingMode 方法设置舍入模式。
6鱼和熊掌不可兼得之CAP定理
什么是 CAP 定理?
CAP 定理是一个分布式系统设计的基本原则。它指出,在一个分布式系统中,无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)三个特性。
一致性 C:每次请求都会获取最新的数据或错误。
在网络分区期间,系统会保持对于客户端的读操作要么返回最新的数据,要么返回错误。
可用性 A:每个请求都会得到响应,但不能保证其中包含最新写入。
无论何时,任何客户端的请求都应该能够得到有效的响应数据,而不会出现响应错误。即使在网络分区期间,系统也会确保对客户端的请求进行响应。不管数据是否为最新。 分区容错性 P:节点之间的网络出现问题之后,系统仍在继续运行。
由于网络不可靠,当消息丢失或延迟到达时,系统仍会继续提供服务而不会挂掉。分区容忍性意味着系统会继续运行,并努力恢复网络分区后的一致性。
CAP 为什么不能兼得?
这是因为在网络分区发生时,为了保证系统的可用性和分区容忍性,系统必须允许分区内的节点继续提供服务。而为了保证一致性,所有节点之间需要相互协调和同步,以确保数据的一致性。然而,在网络分区发生时,由于消息传递的延迟、丢失等问题,无法保证所有节点之间的即时一致性。
所以,当发生网络分区时,分布式系统必须在可用性和一致性之间做出折衷选择。具体来说,系统可以选择在网络分区期间放弃一致性,以保证可用性和分区容忍性,这是常见的解决方案。或者系统可以放弃可用性,在网络分区期间停止对外提供服务,等待分区恢复后再提供一致性的数据。
AP、CP 如何理解?
AP(可用性与分区容忍性):系统能够在网络故障或部分节点失效的情况下继续可用。它侧重于保证系统的稳定性和用户的访问体验。
想象你正在使用一个社交媒体应用,这个应用具有AP属性。即使网络断开或某些服务器出现问题,你仍然可以浏览和发布动态,与朋友互动,尽管可能会遇到一些延迟或数据同步的问题。重点是,你可以随时使用该应用程序,即使在网络不稳定的情况下也能够完成基本操作。 CP(一致性与分区容忍性):系统保证所有节点上的数据一致性,即使在网络分区时也能保持数据的一致性。它侧重于保持数据的准确性和一致性。
举个例子,假设你正在使用一个在线购物应用,这个应用具有CP属性。当你下订单时,系统会确保将订单信息同步到所有节点,以确保数据的一致性。如果发生网络分区,系统可能会暂停交易,直到网络恢复正常,并确保所有节点上的订单数据是一致的。这样可以避免出现因网络问题而导致订单丢失或重复的情况。
额外补充
在分布式系统正常运行时,即不存在网络分区或故障的情况下,的确可以同时满足一致性和可用性,这是因为节点之间可以直接通信来保持数据的一致性,并且系统可以一直对外提供服务。这样的场景下,CAP理论并不适用,因为没有发生需要做出选择的情况。
只有当网络分区或故障发生时,才需要在C和A之间进行权衡选择。在网络分区发生时,为了保证可用性和分区容忍性,系统可能需要放弃一致性,例如采用最终一致性模型。反之,如果一致性是更为重要的需求,系统可以牺牲可用性,在网络分区期间停止对外服务,等待分区恢复后再提供一致性数据。
7,为什么说BigDecimal适合数值计算
使用什么类型来进行数值计算?这个问题在程序员群体中一直都是一个争论激烈的问题,
Int Long Double Float String BigDecimal
如果还能再多几个类型的话,我估计也会有人安排上,究其原因我想大部分都是历史问题。
如果现在让你从 0 ->1 开始设计一个新的系统,相信大家应该大概也许都会优先考虑使用 BigDecimal 进行运算吧,别告诉我你还会用 String,当然如果是只交付不售后的那种,当我没说。让我来设计的肯定是优先考虑 BigDeCimal 运算了。原因的话我们接下来就一起看看 BigDecimal 的设计就明白了。
7.1变量介绍
首先来看一下BigDecimal的类声明以及几个属性:
public class BigDecimal extends Number implements Comparable<BigDecimal> {
/**
* 一个包含整数部分的 BigInteger 对象。
* 某个整数值本身很大,超出基本数据类型的表示范围
* 带小数的值转为整数后值很大,超出基本数据类型的表示范围
*/
private final BigInteger intVal;
/**
* 小数点右侧的位数。
* 它表示了小数的精度,即小数点后的位数。
*/
private final int scale;
/**
* 数值的精度。
* 它指的是 BigDecimal 数值的总位数,包括整数和小数部分。
*/
private transient int precision;
/**
* 缓存的字符串表示。
* 当 BigDecimal 被转换为字符串时,会将其缓存起来,以提高性能。
*/
private transient String stringCache;
// 扩大成long型数值后的值
private final transient long intCompact;
}7.2从例子入手
通过debug来发现源码中的奥秘是了解类运行机制很好的方式。 请看下面的testBigDecimal方法:
@Test
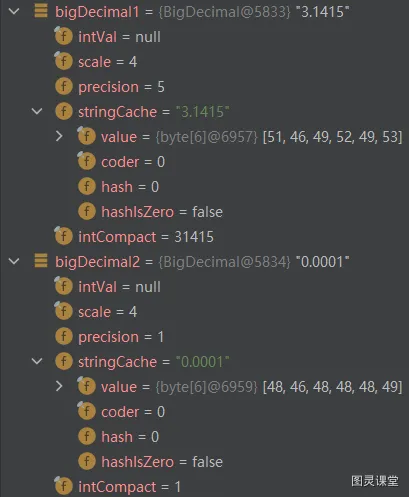
public void calBigDecimal(){
BigDecimal bigDecimal1 = BigDecimal.valueOf(3.1415);
BigDecimal bigDecimal2 = new BigDecimal("0.0001");
BigDecimal bigDecimal = bigDecimal1.add(bigDecimal2);
System.out.println(bigDecimal);
}在 sout 断点,查看debug信息可以发现上述提到的几个属性被赋了值:
接下来进到add方法里面,看看它是怎么计算的:
/**
* 返回 BigDecimal 一个 其值为 (this + augend),其小数位数为 max(this.scale(), augend.scale())。
* 参数:augend – 要添加到此 BigDecimal的值。
* 返回:this + augend
*/
public BigDecimal add(BigDecimal augend) {
// 如果当前 BigDecimal 使用紧凑表示(intCompact != INFLATED)
if (this.intCompact != INFLATED) {
// 如果 augend 也使用紧凑表示(intCompact != INFLATED)
if ((augend.intCompact != INFLATED)) {
// 调用 add 方法执行加法,并返回结果
return add(this.intCompact, this.scale, augend.intCompact, augend.scale);
} else {
// 如果 augend 使用大整数表示(intCompact == INFLATED)
// 调用 add 方法执行加法,并返回结果
return add(this.intCompact, this.scale, augend.intVal, augend.scale);
}
} else {
// 如果当前 BigDecimal 使用大整数表示(intCompact == INFLATED)
if ((augend.intCompact != INFLATED)) {
// 如果 augend 使用紧凑表示(intCompact != INFLATED)
// 调用 add 方法执行加法,并返回结果
return add(augend.intCompact, augend.scale, this.intVal, this.scale);
} else {
// 如果 augend 使用大整数表示(intCompact == INFLATED)
// 调用 add 方法执行加法,并返回结果
return add(this.intVal, this.scale, augend.intVal, augend.scale);
}
}
}根据传入的值,我们可以知道是进入第 12 行的add方法:
/**
* 使用紧凑表示执行两个长整型数值的加法,并返回结果。
*
* @param xs 第一个长整型数值
* @param scale1 第一个数值的小数位数
* @param ys 第二个长整型数值
* @param scale2 第二个数值的小数位数
* @return 加法结果的 BigDecimal 对象
*/
private static BigDecimal add(final long xs, int scale1, final long ys, int scale2) {
// 计算两个数值的小数位数之差
long sdiff = (long) scale1 - scale2;
// 如果小数位数相等
if (sdiff == 0) {
// 直接调用 add 方法执行加法,并返回结果
return add(xs, ys, scale1);
// 如果第一个数的小数位数较多
} else if (sdiff < 0) {
// 检查并调整第一个数的小数位数
int raise = checkScale(xs, -sdiff);
// 将第一个数按 10 的 raise 次方进行缩放
long scaledX = longMultiplyPowerTen(xs, raise);
// 如果缩放后的数值不为 INFLATED(紧凑表示)
if (scaledX != INFLATED) {
// 调用 add 方法执行加法,并返回结果
return add(scaledX, ys, scale2);
// 如果缩放后的数值为 INFLATED(大整数表示)
} else {
// 将第一个数按 10 的 raise 次方进行缩放,并与第二个数相加得到 BigInteger 对象
BigInteger bigsum = bigMultiplyPowerTen(xs, raise).add(ys);
// 根据数值的正负情况,创建新的 BigDecimal 对象并返回
return ((xs ^ ys) >= 0) ?
new BigDecimal(bigsum, INFLATED, scale2, 0) :
valueOf(bigsum, scale2, 0);
}
// 如果第二个数的小数位数较多
} else {
// 检查并调整第二个数的小数位数
int raise = checkScale(ys, sdiff);
// 将第二个数按 10 的 raise 次方进行缩放
long scaledY = longMultiplyPowerTen(ys, raise);
// 如果缩放后的数值不为 INFLATED(紧凑表示)
if (scaledY != INFLATED) {
// 调用 add 方法执行加法,并返回结果
return add(xs, scaledY, scale1);
// 如果缩放后的数值为 INFLATED(大整数表示)
} else {
// 将第二个数按 10 的 raise 次方进行缩放,并与第一个数相加得到 BigInteger 对象
BigInteger bigsum = bigMultiplyPowerTen(ys, raise).add(xs);
// 根据数值的正负情况,创建新的 BigDecimal 对象并返回
return ((xs ^ ys) >= 0) ?
new BigDecimal(bigsum, INFLATED, scale1, 0) :
valueOf(bigsum, scale1, 0);
}
}
}这个例子中,该方法传入的参数分别是:xs=31415,scale1=4,ys=1,scale2=4 该方法首先计算scale1 - scale2,根据差值走不同的计算逻辑,这里求出来是 0,所以进入第一个 if 处理逻辑:
/**
* 使用紧凑表示执行两个长整型数值的加法,并返回结果。
*
* @param xs 第一个长整型数值
* @param ys 第二个长整型数值
* @param scale 结果的小数位数
* @return 加法结果的 BigDecimal 对象
*/
private static BigDecimal add(long xs, long ys, int scale) {
// 执行两个长整型数值的加法
long sum = add(xs, ys);
// 如果加法结果不为 INFLATED(紧凑表示)
if (sum != INFLATED)
// 将加法结果转换为 BigDecimal 对象,并指定小数位数
return BigDecimal.valueOf(sum, scale);
// 如果加法结果为 INFLATED(大整数表示)
// 将两个长整型数值转换为 BigInteger 对象,并执行加法操作
BigInteger bigSum = BigInteger.valueOf(xs).add(BigInteger.valueOf(ys));
// 创建并返回一个新的 BigDecimal 对象,指定数值和小数位数
return new BigDecimal(bigSum, scale);
}这个方法很简单,就是计算和,然后返回BigDecimal对象
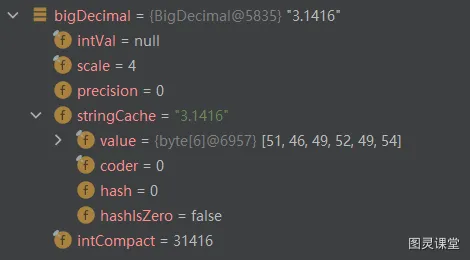
7.3 结论
其实到这里相信大家都知道 Bigdecimal 是如何保证精度的了,其实就是很多小伙伴正在使用的,将对应的数值进行放大,逻辑上将数值的单位进行缩放。而现在这个过程由 Bigdecimal 进行处理了,我们只需要调用相应的方法即可。
至于其他类型,我这边不使用就不跟大家讨论了,还在使用的看观们,快说出你们还在使用的原因,让大家一起开开眼。
数据准备
/**
return (b.signum < 0)? -u : u;
}
/**
* 判断x和y的绝对值的大小
* @param x
* @param y
* @return -1:x<y;0:x=y;x>y:1
*/
private static int longCompareMagnitude(long x, long y) {
if (x < 0)
x = -x;
if (y < 0)
y = -y;
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
/**
* 判断s强转为int的范围
* @param s
* @return
*/
private static int saturateLong(long s) {
int i = (int)s;
return (s == i) ? i : (s < 0 ? Integer.MIN_VALUE : Integer.MAX_VALUE);
}
/**
* 内部打印程序
* @param name
* @param bd
*/
private static void print(String name, BigDecimal bd) {
System.err.format("%s:\tintCompact %d\tintVal %d\tscale %d\tprecision %d%n",
name,
bd.intCompact,
bd.intVal,
bd.scale,
bd.precision);
}
/**
* 检查这个BigDecimal的内部不变量。这些不变量包括:
* 1、对象必须初始化;intCompact必须不是INFLATED,否则intVal是非空的。这两个条件都可能成立。
* 2、如果intCompact和intVal和set的值都是一致的。
* 3、如果精度(precision)非零,则必须具有正确的值。
* 注意:由于这是一个审计方法,我们不应该更改这个BigDecimal对象的状态。
* @return
*/
private BigDecimal audit() {
if (intCompact == INFLATED) {
if (intVal == null) {
print("audit", this);
throw new AssertionError("null intVal");
}
// 检查精度(precision)
if (precision > 0 && precision != bigDigitLength(intVal)) {
print("audit", this);
throw new AssertionError("precision mismatch");
}
} else {
if (intVal != null) {
long val = intVal.longValue();
if (val != intCompact) {
print("audit", this);
throw new AssertionError("Inconsistent state, intCompact=" +
intCompact + "\t intVal=" + val);
}
}
// 检查精度(precision)
if (precision > 0 && precision != longDigitLength(intCompact)) {
print("audit", this);
throw new AssertionError("precision mismatch");
}
}
return this;
}
}BigDecimal在计算时,实际会把数值扩大10的n次倍,变成一个long型整数进行计算,整数计算时自然可以实现精度不丢失。同时结合精度scale,实现最终结果的计算。
8,String能存储多少个字符
- 1 首先String的length方法返回是int。所以理论上长度一定不会超过int的最大值。
- 2 编译器源码如下,限制了字符串长度大于等于65535就会编译不通过
private void checkStringConstant(DiagnosticPosition var1, Object var2) {
if (this.nerrs == 0 && var2 != null && var2 instanceof String && ((String)var2).length() >= 65535) {
this.log.error(var1, "limit.string", new Object[0]);
++this.nerrs;
}
}Java中的字符常量都是使用UTF8编码的,UTF8编码使用1~4个字节来表示具体的Unicode字符。所以有的字符占用一个字节,而我们平时所用的大部分中文都需要3个字节来存储。
//造数据
public void test01(){
int i = 65535;
String s01 = "";
while (i-- > 0) {
s01 += "D";
}
System.out.println(s01.length());
System.out.println(s01);
}
//65534个字母,编译通过
String s01 = "DD..D";
//21845个中文”百“,编译通过
String s02 = "百百...百";
//一个英文字母d加上21845个中文”百“,编译失败
String s03 = "d百百...百";对于s01,一个字母d的UTF8编码占用一个字节,65534字母占用65534个字节,长度是65534,字符串长度和字符串常量存储都没超过限制,所以可以编译通过。
对于s02,一个中文占用3个字节,21845个正好占用65535个字节,而且字符串长度是21845,字符串长度和字符串常量存储也都没超过限制,所以可以编译通过。
对于s03,一个英文字母d加上21845个中文”百“占用65536个字节,超过了字符串常量存储最大限制,编译失败。
3 JVM规范对常量池有所限制。量池中的每一种数据项都有自己的类型。Java中的UTF-8编码的Unicode字符串在常量池中以CONSTANTUtf8类型表示。CONSTANTUtf8的数据结构如下:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}我们重点关注下长度为 length 的那个bytes数组,这个数组就是真正存储常量数据的地方,而 length 就是数组可以存储的最大字节数。length 的类型是u2,u2是无符号的16位整数,因此理论上允许的的最大长度是2^16-1=65535。所以上面byte数组的最大长度可以是65535
4,运行时限制
String 运行时的限制主要体现在 String 的构造函数上。下面是 String 的一个构造函数:
public String(char value[], int offset, int count) {
...
}上面的count值就是字符串的最大长度。在Java中,int的最大长度是2^31-1。所以在运行时,String 的最大长度是2^31-1。
但是这个也是理论上的长度,实际的长度还要看你JVM的内存。我们来看下,最大的字符串会占用多大的内存。
// 在JDK 9之前,Java的String对象使用UTF-16编码,以char数组存储字符,每个char占用2个字节。
// 即使在JDK 9及以后,如果字符串包含非LATIN1字符,如中文字符,则仍使用UTF-16编码。
// 最坏情况下继续使用utf-16编码
(2^31-1)*2/1024/1024/1024 = 4GB所以在最坏的情况下,一个最大的字符串要占用 4GB的内存。如果你的虚拟机不能分配这么多内存的话,会直接报错的。
9JDK9为何要将String的底层实现由char[]改成了byte[]
如果你不是 Java8 的钉子户,你应该早就发现了:String 类的源码已经由 char[] 优化为了 byte[] 来存储字符串内容,为什么要这样做呢? 开门见山地说,从 char[] 到 byte[],最主要的目的是为了节省字符串占用的内存。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
9.1byte[] 为什么就能节省内存空间呢?
众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-16 编码,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
也就是说,使用 char[] 来表示 String 就导致了即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
而实际开发中,单字节的字符使用频率仍然要高于双字节的。
当然了,仅仅将 char[] 优化为 byte[] 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
换句话说,对于:
String name = "baili";这样的,使用 Latin-1 编码,占用 5 个字节就够了。
但对于:
String name = "百里";这种,木的办法,只能使用 UTF16 来编码。因为这两个字符超出了 Latin-1 的范围。在 Java 中,这两个字符会占用 4 个字节(每个字符 2 字节)。
针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
也就是说,从 char[] 到 byte[],中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节。
9.2 为什么用UTF-16而不用UTF-8呢?
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
如果只有一个字节,那么最高的比特位为 0;
如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
0xxxxxxx:一个字节;
110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
那有小伙伴可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。 ●
- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00DFFF 之间的双字节存储。
但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
所以UTF-16在Java的世界里,就可以视为一个定长的编码。
10有限内存如何实现读取超限数据并统计数字重复次数,并获取最大的重复数
在有限内存的前提下,想要实现读取超限数据并完成统计功能的方案有很多。
比如说:分块读取使用 Map 来进行统计,但这种情况只能处理理想情况,文件的数据都是均匀分布,不存在大量唯一值数据;
而如果说文件的数据高度稀疏,大量唯一值,这样就会导致 Map 爆内存出现 OOM;
针对这种场景可以进一步优化,将文件分块读取,再将读取的数据 hash 到不同的文件中,然后在完成对应的统计。
当然除了这种处理方案还比如采用 MMAP 映射不进行分片,逐个处理,但这种也可能会出现统计 Map 爆内存 OOM 还比如采用一些算法来进行处理等等。
那有没有一种“标准答案”?
给大家提供一种实现思路:动态滑动窗口
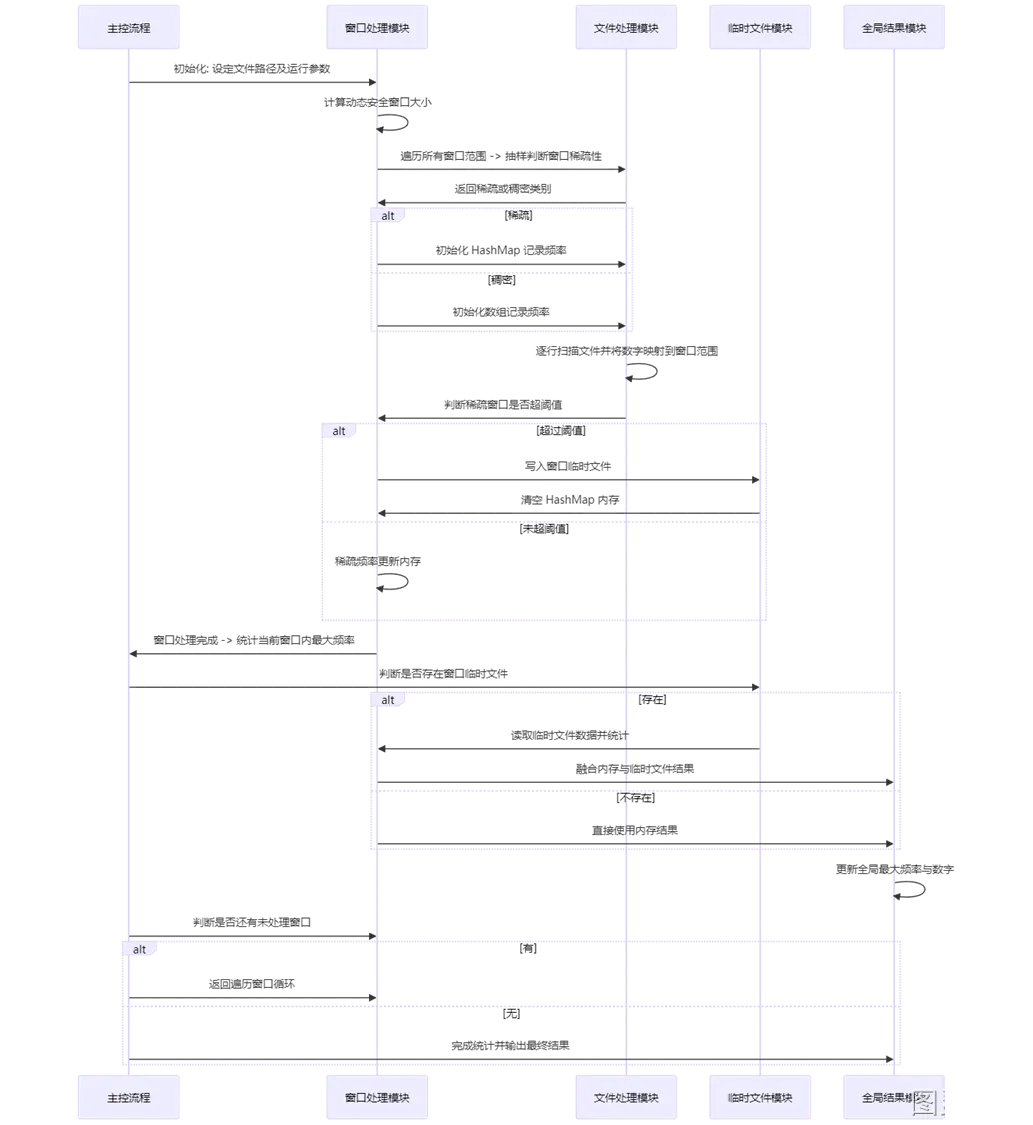
package com.baili.springboot3.utools;
* 抽样判断窗口是否稀疏
*/
private static boolean isSparseWindow(long windowStart, long windowEnd, String filePath) throws IOException {
int sampleSize = 1000; // 设定采样大小
int matchCount = 0; // 落在该窗口范围内的数字计数
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String line;
int sampleCount = 0;
while ((line = reader.readLine()) != null && sampleCount < sampleSize) {
long number = Long.parseLong(line.trim());
if (number >= windowStart && number < windowEnd) {
matchCount++;
}
sampleCount++;
}
}
double density = (double) matchCount / sampleSize; // 计算窗口的相对数据密度
return density < 0.01; // 判断是否是稀疏窗口
}
/**
* 稀疏窗口数据写入临时文件
*/
private static void dumpToDisk(Map<Long, Integer> windowData, long windowStart, long windowEnd) throws IOException {
String fileName = "window_" + windowStart + "_" + windowEnd + ".tmp";
try (BufferedWriter writer = new BufferedWriter(new FileWriter(fileName, true))) { // 追加写入模式
for (Map.Entry<Long, Integer> entry : windowData.entrySet()) {
writer.write(entry.getKey() + "," + entry.getValue() + "\n");
}
}
windowData.clear(); // 清空 HashMap
}
/**
* 统计窗口的最大频率,包含内存和临时文件中的值
*/
private static long[] processWindowMaxFrequency(Map<Long, Integer> sparseFrequency, int[] denseFrequency,
long windowStart, long windowEnd) throws IOException {
long windowMaxNumber = -1; // 窗口出现次数最多的数字
int windowMaxFrequency = -1; // 窗口最大频率
// 密集模式最大值
if (denseFrequency != null) {
for (int i = 0; i < denseFrequency.length; i++) {
if (denseFrequency[i] > windowMaxFrequency) {
windowMaxFrequency = denseFrequency[i];
windowMaxNumber = windowStart + i;
}
}
}
// 稀疏模式最大值
if (sparseFrequency != null) {
for (Map.Entry<Long, Integer> entry : sparseFrequency.entrySet()) {
if (entry.getValue() > windowMaxFrequency) {
windowMaxFrequency = entry.getValue();
windowMaxNumber = entry.getKey();
}
}
}
// 合并临时文件中的频率数据
String fileName = "window_" + windowStart + "_" + windowEnd + ".tmp";
File tempFile = new File(fileName);
if (tempFile.exists()) {
try (BufferedReader reader = new BufferedReader(new FileReader(tempFile))) {
String line;
while ((line = reader.readLine()) != null) {
String[] parts = line.split(",");
long number = Long.parseLong(parts[0]);
int frequency = Integer.parseInt(parts[1]);
if (frequency > windowMaxFrequency) {
windowMaxFrequency = frequency;
windowMaxNumber = number;
}
}
}
// 删除临时文件
tempFile.delete();
}
return new long[]{windowMaxNumber, windowMaxFrequency};
}
}